تا به حال چندین مقاله در خصوص فناوری تبدیل گفتار به نوشتار و کاربردهای آن منتشر کرده ایم؛ همچنین از دستیارهای صوتی که از فناوری تبدیل گفتار به نوشتار در آنها استفاده میشوند و لزوم استفاده از آنها در اپلیکیشنها گفته ایم. اما در این مقاله به صورت اختصاصی میخواهیم به ساختار فناوری تبدیل گفتار به نوشتار بپردازیم و بگوییم فناوری تبدیل گفتار به نوشتار چگونه کار میکند؟ و چطور یک ماشین میتواند صوت را به متن تبدیل کند. برای آشنایی بیشتر با کاربرد تبدیل گفتار به نوشتار میتوانید ابزار تایپ صوتی زیر را تست کنید (با زدن بر روی علامت میکروفن به ضبط گفتار بپردازید).
تبدیل گفتار به نوشتار چیست؟
فناوری تبدیل گفتار به نوشتار یا بازشناسی گفتار یا speech recognition میتواند فایل صوتی را (اعم از صحبتهای افراد، صوت ضبط شده، صدای یک فیلم و…) به نوشتار تبدیل کند یا به عبارتی گفتار را تبدیل به نوشتار نماید.
فناوری تبدیل گفتار به نوشتار در حقیقت نوعی برنامه، اپلیکیشن، نرم افزار و… است که محتوای صوتی را گرفته و با پردازش محتوای آن صوت، را به کلمات مکتوب تبدیل میکند. فناوری تبدیل گفتار به نوشتار، همانطور که گفته شد یک فناوری بر پایه هوش مصنوعی است که قادر به تهیه متن از یک گفتوگوی شفاهی و محتوای صوتی موجود و یا تایپ در لحظه میباشد.
تبدیل گفتار به نوشتار چگونه کار میکند؟
تبدیل گفتار به نوشتار بخشی از فناوری بازشناسی گفتار است که به سادگی میتوان مسئله بازشناسی گفتار را در این فرمول احتمالاتی شرطی خلاصه کرد:

به این معنی که ما به دنبال رشتهای از کلمات خروجی هستیم که با توجه به سیگنال ورودی موجود، محتملترین رشته کلمات خروجی را به ما نشان دهند. مسئله را میتوان بر اساس این فرمول توضیح داد و گفت وظیفهی ASR (Automatic Speech Recognition) پیدا کردن محتملترین رشتهی کلمات است، که این احتمال برابر است با احتمال شنیده شدن سیگنال صوتی با فرض کردن دنبالهی کلمات مورد نظر ضرب در احتمال تولید شدن یک دنبالهی کلمات مفروض در زبان. زمانی که این دو را باز کنیم، در واقع دو پایه اساسی یک سیستم بازشناسی گفتار به دست میآید که عبارتند از:
۱.مدل آکوستیکی
۲.مدل زبانی
وظیفهی مدل آکوستیکی اعمال یک نگاشت از ویژگیهای ورودی (مانند spectrogram، lmfb یا mfcc) که از سیگنال استخراج شدهاند، به ویژگیهای زبانی سطح بالاتر (مثلا واج، سهواج، نویسه یا توکن) است. مدل زبانی نیز مشخص میکند که احتمال دنبالهی کلمات مورد نظر در آن زبان به چه میزان است. این فرمول شاید سادهترین و پایهایترین فرمول بازشناسایی گفتار باشد.
سیگنال صوتی وارد یک سری پیش پردازشها میشود. به عنوان مثال در زمانهایی که سکوت است، سیگنال صوتی را بریده شده یا نویز را کاهش داده میشود؛ استخراج ویژگیها نیز بخشی از پیش پردازش است. ویژگیهای نامبرده از سیگنال صوتی محاسبه میگردد. در نهایت با ترکیب دانش موجود در مدل زبانی و پیشبینی مدل آکوستیکی، محتملترین دنبالهی کلمات توسط برنامه نویس دیکود میشود.

روشهای بازشناسایی گفتار
به صورت کلی تلاشها یا روشهایی که در زمینه پردازش گفتار شده را میتوان به سه دسته تقسیم کرد:

مدل گاوسین-مدل مخفی مارکف
مدلهای مخلوط گاوسین-مدل مخفی مارکف که به Gmm-Hmm نیز معروف است و تا حدود 25 سال پیش بدون هیچ رقیب دیگری برای بازشناسایی گفتار استفاده میشدند؛ این مسئله ادامه داشت تا زمانی که در مقاله معروفی در سال ۲۰۰۶ که توسط یکی از افراد یسیار مهم در زمینه deep learning یعنی دکتر هینگتون ارائه شد، شبکههای عصبی باور عمیق یا DBN ها جایگزین مدل مخلوط گاوسین شدند. اما با این حال باز هم از مدل مخفی مارکف برای شبیه سازی زمانی استفاده میشد. در نهایت، طی سالهای اخیر مدل سرتاسری شبکههای عمیق بازگشتی معرفی شدند که دو مدل قبلی را باهم ترکیب کرده و در یک شبکه عمیق به کار میبردند.
شماتیک کلی این مدلها را در میتوان در تصویر زیر مشاهده کرد. برای توضیح مختصر تصویر میتوان گفت که ما در این مدل از سیگنالهای صوتی، یکسری ویژگی استخراج میکنیم. این ویژگیها میتوانند expectogram یا nfcc باشند. با کمک مدل مخلوط گاوسین، یک آکوستیک مدلی را ساخته و سپس از خروجی همان آکوستیک مدل، یا در واقع از آواهایی که به دست آمده در یک شبکه HMM، مدلسازی زمانی انجام میشود و در نهایت به متن میرسد.
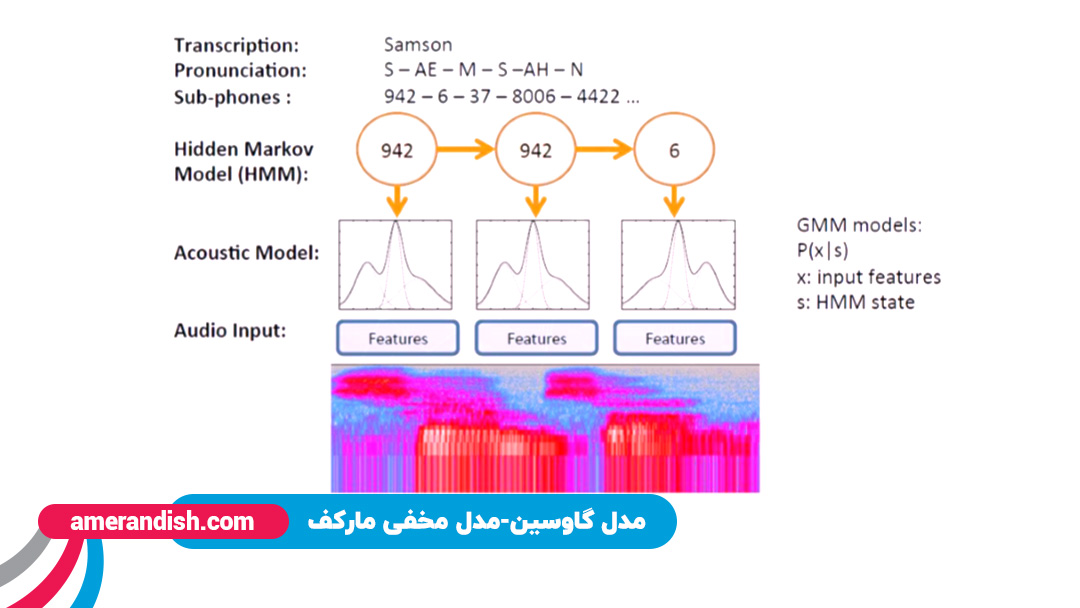
ساختار مدل شبکه عصبی باور عمیق-مدل مخفی مارکف
در شبکههای باور عمیق نیز همان اتفاق میافتد. در این موقعیت میتوان expectogram و یا حتی ورودی خام سیگنال صوتی و MCC را داشت. تنها تفاوت آن با مدل قبلی آن است که به جای مدل گاوسین، از یک شبکه باور عمیق استفاده میشود.
تا قبل ۲۰۰۶ امکان آموزش شبکههای بزرگ وجود نداشت، در آن زمان همهی افراد فعال در حوزه هوش مصنوعی میدانستند که با افزایش تعداد لایهها قاعدتا میتوان نتایج بهتری گرفت و به اصطلاح به درک بالاتری از آن ورودی رسید. یعنی هرچه تعداد لایهها زیادتر و عمیقتر باشد میتوان در عمق بیشتر درک بهتری از ورودی پیدا کرد. اما امکان آموزش این شبکهها به دو دلیل وجود نداشته است: اولین دلیل این است که برای انجام این کار الگوریتمی وجود نداشته است و تا آن زمان تنها میتوان شبکههای ۲ لایه را آموزش داد. زمانی که عمق شبکهها بیشتر میشد نیز از روش نشر بازگشتی استفاده میشد که توانایی انجام درست این کار را نداشت.
با این حال با معرفی شبکههای DBN که با کمک آن میتوانستند لایهها را تک تک آموزش دهند و سپس این لایهها را بر روی هم سوار کردند و شبکه را آموزش دادند. بعد از این اتفاق امکان آن به وجود آمد که به عنوان مثال بتوان با دقت بالاتری آموزش داد. با آمدن این الگوریتم جای مدل مخلوط گاوسین یا GMM ها با شبکههای باور عمیق یا DBM تغییر کرد.
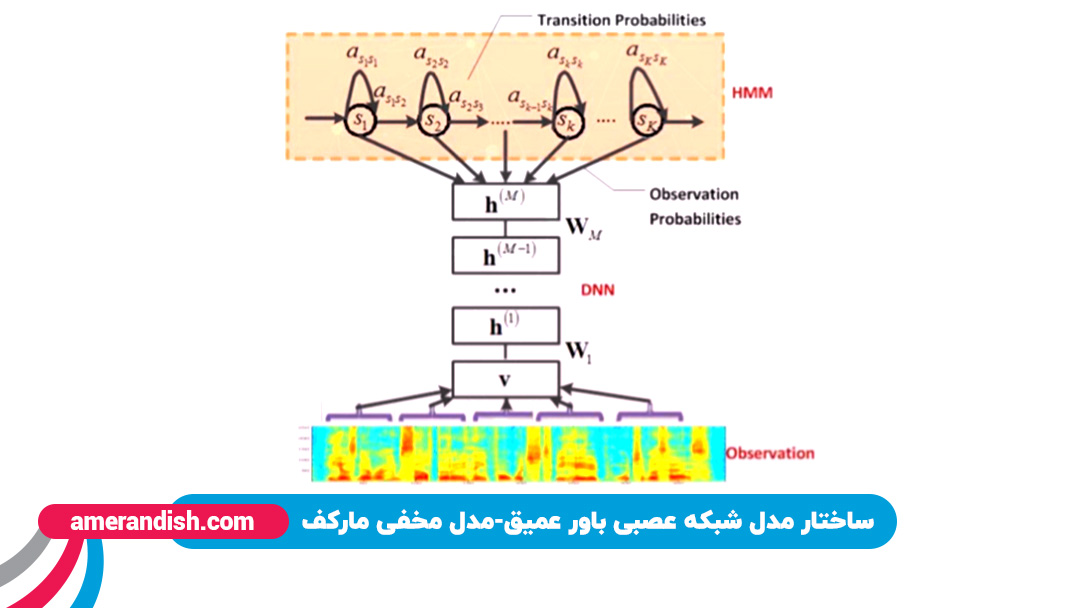
ساختار سرتاسری شبکههای عمیق بازگشتی
یکی از ساختارهای معروف شبکههای عمیق بازگشتی ساختاری همانند تصویر زیر دارد که متعلق به مقاله معروفی است که چند سال پیش توسط “بایدو” منتشر کرد. باتوجه به تصویری که در زیر مشاهده میکنید مرزهای قبلی را بین دو مدل مختلف قبلی وجود ندارد و تمام این اتفاقات در شبکه سرتاسری میافتند؛ در مدلهای سرتاسری یا end to end، ویژگیهای سطح پایین به عنوان ورودی شبکه مورد استفاده قرار میگیرد و خروجیهای سطح بالای زبانی مانند نویسه یا توکن مستقیما توسط مدل آکوستیک پیشبینی میشوند.

فارس آوا، نرم افزاری که گفتار را به نوشتار تبدیل میکند
در حال حاضر در کشور سرویس تبدیل گفتار به نوشتار وجود دارد که به کمک روشهایی که در بالا گفته شد، گفتار را به متن تبدیل میکند. فارس آوا دارای بزرگترین دیتاست فارسی در داخل کشور است. فارس آوا عملیات بازشناسایی گفتار را به کمک روشهای یادگیری عمیق انجام میدهد و این نرم افزار تبدیل گفتار به متن در زبان فارسی امکان ارتباط کلامی انسان با کامپیوتر و یا موبایل را فراهم میکند. این نرم افزار با تکیه بر دانش متخصصان هوش مصنوعی ایرانی و با بهرهگیری از آخرین تکنولوژیهای روز دنیا تولید شده است و به دلیل جمعآوری بزرگترین دیتاست موجود در زبان فارسی و تمرکز ویژه روی این زبان، ضمن بهرهمندی از تنوع گفتاری بسیار وسیع موفق شده تا در رقابت با شرکتهای بزرگی چون گوگل ضریب دقت بالایی داشته باشد.
ویژگیها و قابلیتهای فارس آوا عبارتند از:
- تبدیل گفتار به متن فارسی با دقت و سرعت بالا
- بهرهمندی از آخرین تکنولوژیهای یادگیری عمیق
- تبدیل گفتار به متن به صورت همزمان (Real-Time)
- تشخیص گفتار و صوت در محیطهای نویزی
- پشتیبانی از انواع لهجهها و گویشها
- قابلیت تبدیل گفتار محاورهای به متن
- پشتیبانی از انواع فرمتهای صوتی و ویدیویی
- تبدیل گفتار انگلیسی به متن انگلیسی
- غیر وابسته به گوینده و عدم نیاز به آموزش برای هر فرد
- ارائه پنل تحت وب برای آپلود کردن فایلها جهت پردازش
- بهرهمندی از دایره واژگان (فرهنگ لغت) بسیار وسیع
- تبدیل گفتار به نوشتار به کمک هوش مصنوعی)
همهی موارد ذکر شده باعث شد تا فارس آوا به یکی از کاربردیترین و با کیفیتترین محصولات موجود در بازار امروز ایران، تبدیل شود. فارس آوا سرویسی است که به صورت اختصاصی برای زبان فارسی تولید شده است و واژگان زبان فارسی را به خوبی درک و پردازش میکند. شما میتوانید با خیالی آسوده از نرم افزار فارس آوا استفاده کنید و راندمان و بهرهوری کار خود و یا کارمندان در سازمان و یا کسب و کارتان را افزایش دهید. همچنین فارس آوا از رابط کاربری بسیار سادهای برخوردار است که این امر استفاده همهی افراد از این نرم افزار را بسیار ساده میکند.
برای خرید محصول فارس آوا و یا درخواست دمو محصول تبدیل گفتار به نوشتار به صفحه فارس آوا مراجعه کنید.
در حال حاضر بهترین نرم افزار موجود در زبان فارسی برای تبدیل گفتار به متن، محصول فارس آوا است که طبق تست های صورت گرفته از محصول گوگل در زبان فارسی نیز از کیفیت بالاتری برخوردار است.
محصول فارس آوا از یک دایره واژگان 270 هزار کلمه ای تشکیل شده است، بر روی حوزه های مختلف سفارشی سازی شده، برای مشتریان سازمانی قابلیت نصب در سرورهای مشتری را دارد و از لحاظ قیمتی نیز از سرویس گوگل ارزان تر است.
خیر، در حال حاضر شرکت هایی هستند که از افزونه رایگان گوگل در مرورگر گوگل کروم استفاده میکنند که این موضوع باعث شده تا این سرویس تنها روی این مروگر قابل استفاده باشد. اما محصول فارس آوا که یک محصول بومی است، این محدودیت ها را ندارد.
یکی از مهمترین مزیت های محصول فارس آوا قابلیت بارگذاری فایل های صوتی و ویدئویی در پنل تحت وب آن است که به کاربران این امکان را میدهد تا تمامی آرشیوهای صوتی مورد نیاز خود را در کوتاه ترین زمان ممکن به متن تبدیل کنند.




