اکثر ایستگاههای تلویزیونی برای تولید زیرنویس برای پخش مستقیم برنامه خود، همچنان به منابع انسانی اعتماد میکنند. حتی با وجود سودمندی و مزایای تسلط انسان، زیرنویسها میتوانند در یک پخش از نقطه نظر کیفیت بسیار متفاوت باشد، این تفاوتها از یک بازگردانی بیعیبونقص و کامل تا یک ترجمه و بازگردانی شکسته و نامفهوم متغیر است. حتی در بهترین زیرنویسهای انسانی، اغلب برخی از واژگان به دلیل گفتار سریع، غلط املایی یا طولانی بودن جا انداخته میشوند. در همین زمان، تشخیص گفتار خودکار به سختی برای دستیابی به دقت کافی تلاش کرده تا کاملا جایگزین نیروهای انسانی شود. چگونه ایستگاههای تولیدکننده زیرنویس (با کمک عامل انسانی) اخبار تلویزیونی از اینترنت (بایگانی اخبار تلویزیونی در اینترنت)، زیرنویس بسته شده در خبر را با رونوشتهای ماشینی، API گفتار به نوشتار گوگل کلود (Google’s Cloud Speech-to-text) مقایسه میکنند؟ به عبارت دیگر، در ادامه زیرنویسهای انسانی را با رونوشتهای ماشینی مقایسه خواهیم کرد. با عامراندیش همراه باشید تا با نتایج این مقایسه و تحقیق ارزشمند آشنا شوید.
مقایسه زیرنویس انسانی با رونوشتهای ماشینی
زیرنویس خودکار با کیفیت بالا از فیلم زنده نشاندهنده یکی از مهمترین موارد تشخیص گفتار ماشینی است. در حالی که سیستمهای رونویسی ماشینی طی سالهای گذشته به طرز چشمگیری بهبود یافتهاند، اما هنوز در مقایسه با زیرنویسهای تولید شده توسط انسان یک فاصله قابلتوجهی دارند که باعث میشود از رونوشتهای انسانی عقبتر ایستند. این پرسش در اینجا مطرح است که آیا آخرین نسل از مدلهای تشخیص گفتار بهینه شده برای زیرنویسهای ویدیویی، میتوانند سرانجام به تسلطی نزدیک به انسان دست پیدا کنند؟
API گفتار به نوشتار گوگل کلود، مدلهای مختلف تشخیص گفتار را ارائه میدهد که یکی از آنها، تنها برای رونویسهای ویدیویی تنظیم شده اشت. پرسشی که در اینجا ممکن است ذهن شما را به خود مشغول کند این است که چگونه این API قادر است تا در فضای پر هرجومرج اخبار تلویزیونی عملکردی بالایی داشته باشد، بهطوریکه از خواندن اخبار استادیو به صحنه گزارشها رفته و از آنجا به سوی پنلهای یک میزگردی رود که متخصصان در آنجا مشغول صحبت با یکدیگرند و از این پنل به سوی تبلغاتی حرکت کند که روند گفتاری آنان بسیار سریع است.
زیرنویسهای انسانی با رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) چه قدر تفاوت دارند؟
برای کشف این مسئله مهم، زیرنویسهای ایستگاههای مهم خبری مانند CNN، MSNBC، Fox News، پخشهای صبحگانه و عصرگانه کانالهای وابسته سانفرانسیسکو مانند KGO (ABC)، KPIX (CBS)، KNTV (NBC) و KQED (PBS) از 15 تا 22 آپریل 2019 (جمعا نزدیک 812 ساعت اخبار تلویزیونی) را در نظر گیرید که تمامی ویژگیهای متفاوت این رونویسیها توسط رونوشت API گفتار به نوشتار گوگل کلود آنالیز و تجزیهوتحلیل شده است.
برای درک تاثیر زیرنویسهای انسانی بر نتیجه متن آنالیز ماشینی، هر دو زیرنویس انسانی و رونوشت ماشینی را از طریق API زبان طبیعی گوگل برای استخراج موجودیت، پردازش شدند.
API زبان طبیعی گوگل در هر 6.97 ثانیه در رونویسهای خودکار، یک وجودیت را تشخیص داد ولی در زیرنویسهای انسانی تنها در 11.63 ثانیه موفق به تشخیص یک وجودیت گردید.
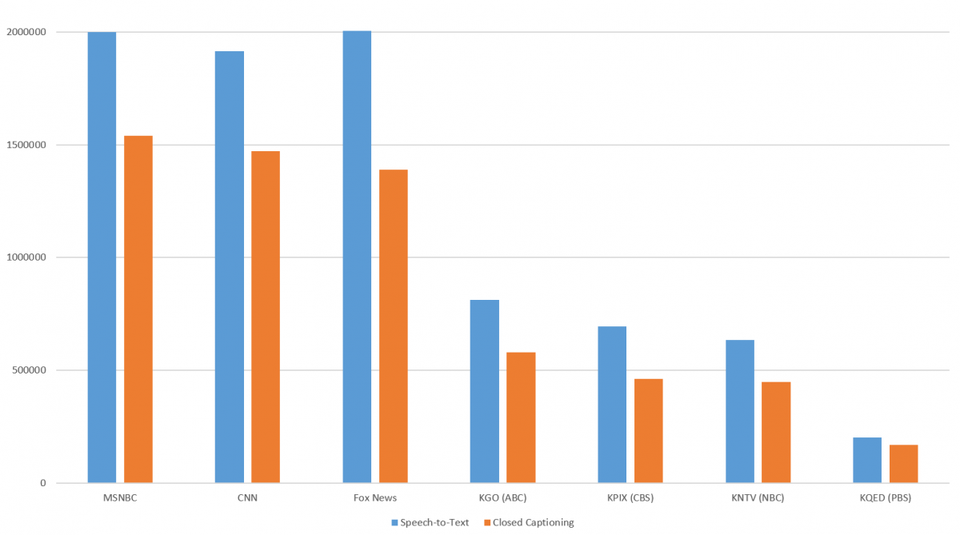
گراف زیر، متوسط شمار ثانیهها در هر موجودیت در هر 7 ایستگاه بین رونوشتهای خودکار و زیرنویسهای انسانی مقایسه کرده است:
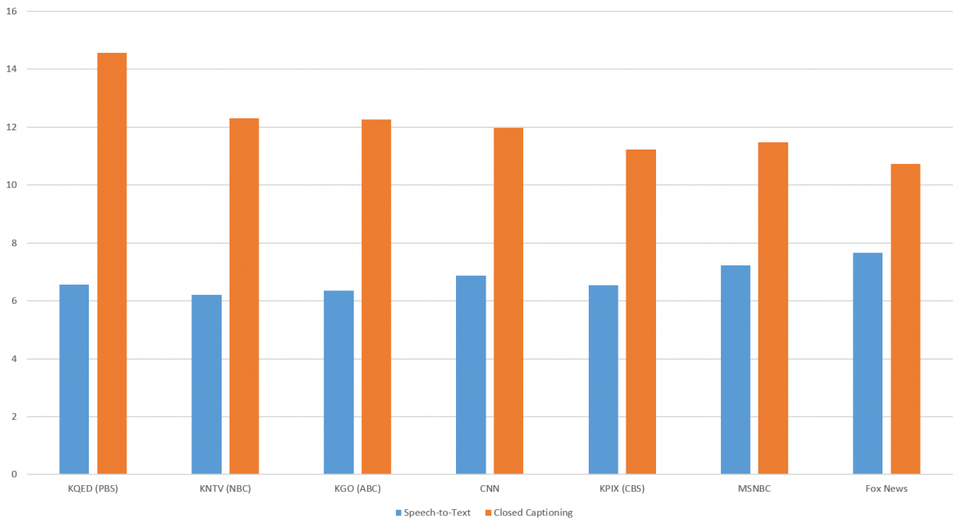
بلافاصله مشخص شد که رونویسهای خودکار (گفتار به نوشتار گوگل کلود) به صورت پایدار چگالی و تراکم بیشتری از موجودیتهای تشخیصی در مقایسه با زیرنویسهای انسانی تولید میکنند. این تراکم از 1.4 برابر بیشتر برای Fox News تا 2.2 برابر بیشتر برای PBS متفاوت است.
به نظر میرسد که دلیل اصلی چنین موضوعی آن باشد که رونوشتهای ماشینی از حروف بزرگ به صورت صحیحتری استفاده کردهاند ولی رونویسهای انسانی این موضوع را رعایت نکردهاند. API زبان طبیعی گوگل (Google Natual language API) برای شناسایی و تشخیص موجودیتها و مرزهای متنی و همچنین برای تشخیص نامها از دیگر واژگان معمولی، متکی به همین رعایت بزرگنویسی حروف است.
تفاوت معناداری بین موجودیت زیرنویس انسانی و رونوشت ماشینی (گفتار به نوشتار گوگل کلود) برای ایستگاه خبری PBS، مخصوصا به دلیل تراکم بالای خطاهای تایپی در زیرنویسهای انسانی نمایان شد که هر دو تحت تاثیر موجودیت ذکر شده خود هستند و به اندازه کافی جریان دستوری متن را قطع کرده به طوریکه در توانایی API در تشخیص و شناسایی مرزهای موجودیت تاثیر میگذارند. در حقیقت، نمودار 2 تا حدی سطح خطای رونویسهای انسانی واژه به واژه برای هر ایستگاه را نشان میدهد.
یک عامل مهم در مقایسه زیرنویس انسان با رونویس ماشینی این است که زیرنویسهای انسانی، از زیرنویسی تبلیغاتی خودداری کرده، درحالیکه رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) تمامی واژگان را شامل میشود و تفاوتی بین آنان قایل نیست. این بدان معناست که ایستگاههایی که مدت زمان بیشتری به تبلیغات اختصاص میدهند، تفاوت بزرگتری را نشان میدهند.
یکی از محدودیتهای این گراف آن است که تنها تراکم موجودیتهای ذکر شده را نشان میدهد، و اینکه تا چه اندازه مطابقت بین رونوشتهای ماشینی و زیرنویسهای انسانی وجود دارد، ساکت میماند. آنان میتوانند تعداد مشابهی از موجودیتها را داشته باشند ولی به دلیل خطای انسانی و ماشینی استخراج این موجودیتها میتوانند کاملا با یکدیگر متفاوت باشند.
برای آزمایش این مهم، یک هیستوگرام از تمامی موجودیتهای استخراج شده، گردآوری شده و ضریب همبستگی پیرسون برای هر ایستگاه بین موجودیتهای زیرنویسهای انسانی و موجودیتهای رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) محاسبه شده که نتایج در گراف زیر قابل مشاهده است.
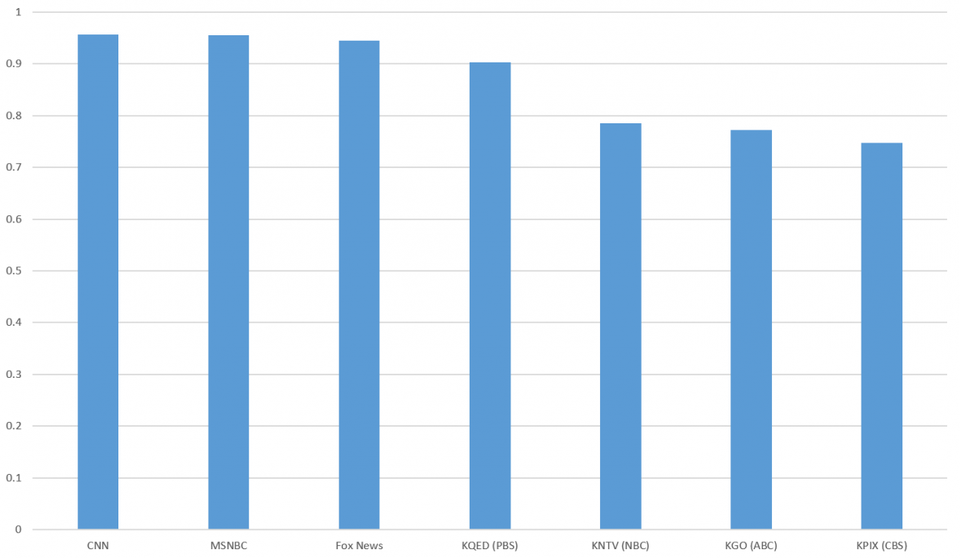
در میان هر 7 ایستگاه، ضریب همبستگی کل برابر بود با r=0.95، ضریب دقیق همبستگی برای ایستگاههای زیر به قرار زیر است:
- CNN & MSNBC: r=0.96
- Fox News: r=0.97
- CBS: r=0.75
جالب اینجاست که 3 ایستگاه ملی بیشترین همبستگی و 4 ایستگاه شبکه، کمترین میزان همبستگی را دارا بودند.
یک توضیح ممکن آن است که از آنجاکه ایستگاههای شبکه تنها شامل پخشهای عصرانه و صبحگانه هستند، زمان پخش تبلیغات برای این ایستگاهها، قسمت بیشتری از محتوای آنان را تشکیل میدهد.
مقایسه رونوشتها (گفتار به نوشتار گوگل کلود) و زیرنویسهای انسانی از طریق موجودیتهای API-استخراج شده، یک نگاهی اجمالی و سریع بر چگونگی این تفاوتها ارایه میدهد که میتواند بر الگوریتمهای درک ماشین تاثیرگذار باشد. در همین زمان، بزرگنویسی حروف و اشتباهات تایپی میتواند یک تاثیر عمیقی بر سیستمهای یادگیری متنی امروز داشته باشند؛ این مشاهدات در نتیجههای بالا کاملا قابل درک است.
مقایسههای مشابه هنگام اعمال متن به رونوشتها یا زیرنویسهاچگونه خواهند بود؟
ننمودار زیر، شمار کل واژگان یکتا و منحصربهفرد را توسط ایستگاه نشان میدهد؛ این نمودار مشخص میسازد در بیشتر ایستگاهها واژگان مشابهی بین رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) و زیرنویسهای انسانی وجود دارد. برای مثال، شمار واژگان منحصربهفرد (در زیرنویس انسانی) در شبکه PBS، 1.6 برابر بیشتر از رونوشت ماشینی است. برای درک علت این مهم، بررسی دقیقی صورت گرفت و نتایج نشان داد که تقریبا همگی آنان، اشتباهات تایپی بوده که بازتابدهنده میزان خطای بالای زیرنویس انسانی است.
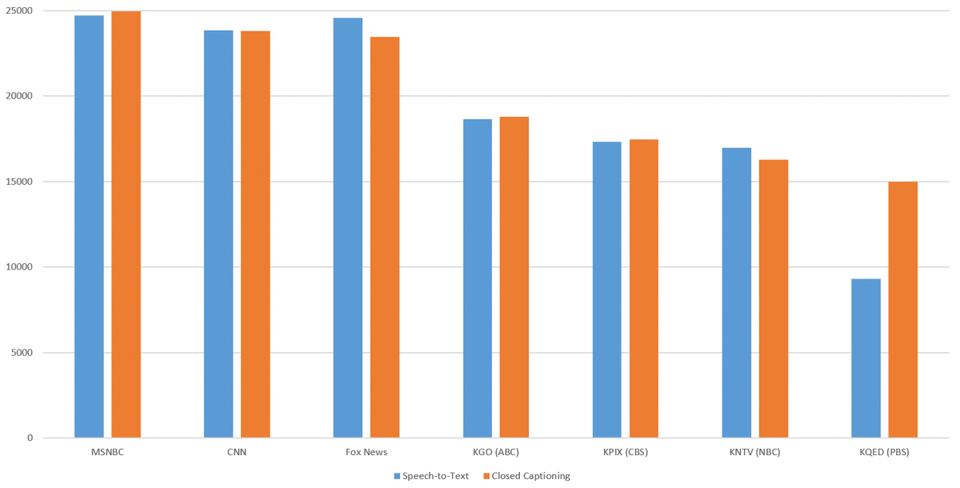
با نگاهی به تعداد کل کلمات گفته شده، نمودار زیر نشان میدهد که برای همه ایستگاهها کلمات متمایز بیشتری نسبت به زیرنویسهای بسته شده در متن ثبت شدهاند، که در درجه اول منعکسکننده زمان پخش تبلیغات بدون عنوان است. این یکی از دلایلی است که زیرنویس انسانی شبکه PBS تعداد کلمات گفتاری تقریبا برابری با رونوشت ماشینی (گفتار به نوشتار گوگل کلود) دارند.
تعداد واژگان بیشتر در CNN، MSNBC و Fox News نشاندهنده بررسی کل زمان پخش هفتگی آنهاست، در حالی که چهار ایستگاه شبکه فقط شامل پخشهای صبحگانه و عصرگانه است.
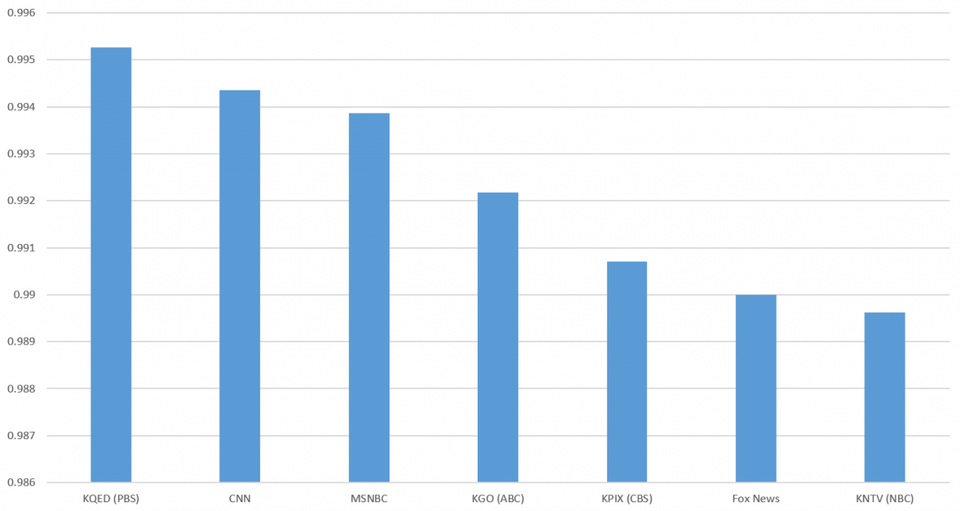
نمودار زیر همبستگی پیرسون واژگان زیرنویس و متن را نشان میدهد. فقط واژگانی در نظر گرفته شدهاند که اولا عدد نبوده و دوما حداقل پنج بار در طول زمان پخش ترکیبی از هفت ایستگاه نمایش داده شدهاند؛ که در مجموع 27876 واژه متمایز است.
هر هفت ایستگاه همبستگی بالاتر از 0.989 دارا بودند، این رقم بیانگر این است که علیرغم تفاوتهایشان، کل واژگان استفاده شده چه در زیرنویس انسانی و چه در رونوشت ماشینی بسیار شبیه به هم بودهاند.
با وجود واژگان مشابه بین رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) و زیرنویسهای انسانی، آزمایشهای واقعی بیشتر تفاوتهای میان زیرنویسهای انسانی و رونوشتهای ماشینی را آشکار میگرداند.
برای هر پخش هم زیرنویس انسانی و هم رونوشت ماشینی به حروف بزرگ تبدیل شده و حروفی غیر از ASCII به فاصلهها تبدیل گشتند. متن حاصل به دو بخش تقسیم شد؛ این دو بخش شامل:
1- واژگانی است که در مرزهای فاصله و دو فایلی که از طریق standard Linux diff utility اجرا میشود، وجود دارند.
2- بخش دیگر شامل تقسیم تعداد کل واژگان نشانهگذاری شده تغییر یافته بر تعداد کل واژگان مقایسهشده دارای تراکم تغییر است
در کل، زیرنویسها و رونوشتها با درصدی در حدود 63% با هم مطابقت داشتند. این مطابقت در CBS به 58% و در FBS & CNN به 68% میرسد.
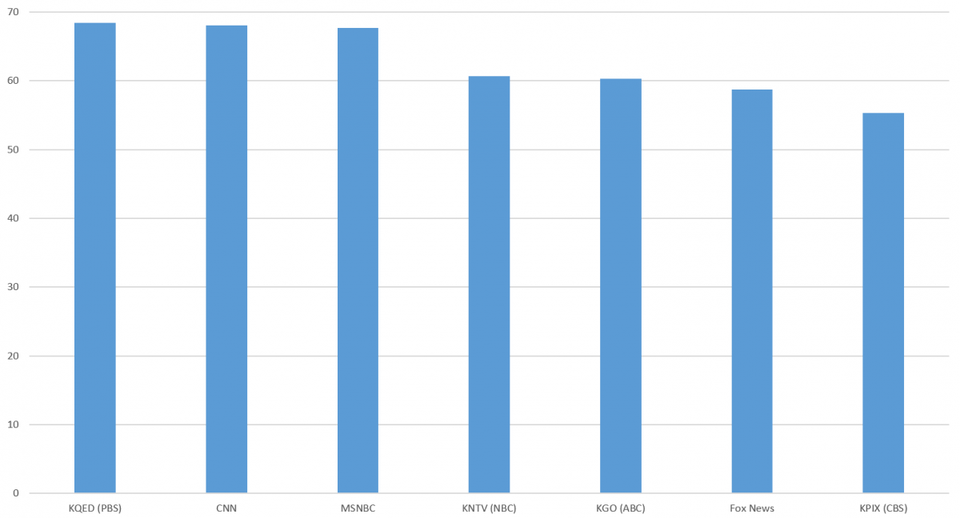
از اینرو درصدها با توجه به کیفیت تشخیص گفتار مدرن، به طور غیرمنتظرهای کم به نظر میرسد.
یک بررسی دقیق از تفاوتها توضیح میدهد که چرا: رونوشت ماشینی (مانند گفتار به نوشتار گوگل کلود) به طور معمول بازگردانی وفادارانهتر و دقیقتر از زیرنویس انسانی را ارایه میدهند.
برای مثال، زیرنویسهای ارایه شده در CNN، بسیار کوتاه (بدون بیان اینکه این افراد دقیقا که هستند) و اینگونه است که “دانا باش (Dana Bash)، گزارشگر جرم و عدالت، شیمون پروکوپز (Shimon Prokupecz) و ایون پرز (Even Perez)”. درحالیکه رونوشت ماشینی عبارت بالا را اینگونه دقیق بیان میدارد: ” خبرنگار سیاسی CNN، Dana Bash و شیمون پروکوپز، گزارشگر جرم و عدالت CNN و خبرنگار ارشد دادگستری ایوان پرز (Evan Perez)”. همانطور که میبینید رونوشت ماشینی با ذکر عنوان افراد، مفهوم بهتری ارایه کرده است.
به همین ترتیب، دقیقه بعدی همان پخش شامل چندین تفاوت بارز است، مانند تفاوت میان “guid post” در زیرنویس انسانی در برابر رونوشت صحیح ماشینی”guidposts”. به همین ترتیب، در حالیکه زیرنویس حاوی عبارت “که او به من گفت (that he told me)” است، رونوشت ماشینی (مانند گفتار به نوشتار گوگل کلود) عینا عبارت گفته شده توسط یکی از اعضای شرکتکننده در میزگرد را بیان میدارد: ” that he that he told me”.
نه زیرنویس و نه رونویس عدم تطابق گفتاری را ضبط نمیکنند؛ این عدم تطابق با API گوگل طراحی شده تا از رونویسی صداهایی مانند “اوووم” یا “ارر” اجتناب شود.
این نشان میدهد که رونوشت مکانیزه ممکن است وفاداری بالاتری نسبت به زیرنویسهای انسانی در بیان واژه به واژه گوینده را داشته باشند. واقعیت این است که رونوشتهای ماشینی (مانند گفتار به نوشتار گوگل کلود) شامل رونویسهای تبلیغاتی نیز میشوند، در حالیکه زیرنویس انسانی از زیرنویس کردن آنان خودداری میکنند.
این امر پیشنهاد میدارد که مقایسه بهتر آن است که هرگونه اختلاف که شامل متن افزوده شده به رونوشتهای ماشینی (متنهای تبلیغاتی) را حذف کنیم. این روش، هنوز واژگانی از زیرنویسهای انسانی را بر میشمارد که از متن رونوشت ماشینی حذف شدهاند، و همچنین واژگانی را لحاظ میکند که در هر دو، زیرنویس انسانی و رونوشت ماشینی (گفتار به نوشتار گوگل کلود) وجود دارند ولی هجیهای آنان متفاوت است.
این نتایج در نمودار زیر نشان داده شده است؛ در این نمودار، تشابه میان رنوشتهای ماشینی و زیرنویسهای انسانی را با متوسط 92٪ نشان میدهد که دامنه آن از 87% برای PBS تا 93٪ برای CNN و MSNBC متغیر است.
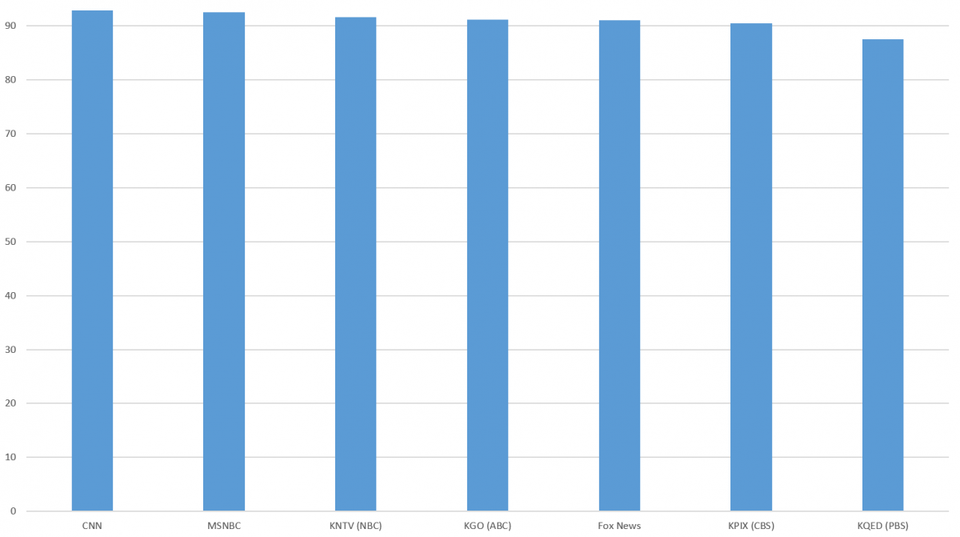
این امر روشن میسازد که بیشتر اختلافات بین رونوشتهای ماشینی (گفتار به نوشتار گوگل کلود) و زیرنویسهای انسانی، لحاظ شدن متنهای تبلیغاتی در رونوشت ماشینی و وفاداری بالاتر ماشین در ضبط جزئیاتی مانند تکرار و عنوانهای کامل گفتاری است.
با دقت بیشتر به تفاوتهای باقیمانده ، بسیاری از آنها در واقع اشتباهات تایپی در زیرنویسهای تولید شده توسط انسان هستند.
برخی از اختلافات باقی مانده نیز حول برخی از خوانندگان اخبار و نامهای اعضای میزگرد رادیویی و یا تلویزیونی است که ماشین اشتباهاتی در هجی آوایی و تلفظ اشتباه نام این اعضا را دارد، مثلا نام مولر “Mueller” به عنوان مادر “mother” ذکر شده است.
بنابر آنچه در بالا گفته شد، تراز واقعی بین انسان و ماشین بیش از 92% است.
از همه مهمتر، درجه بالای خطا در زیرنویسهای انسانی به این معنی است که از نظر فنی دارای استاندارد طلایی نیستند. بنابراین، 8٪ آهنگ اختلاف بین انسان و ماشین به این معنی نیست که ماشین دارای آهنگ 8٪ خطاست. در واقع، بخش قابل توجهی از این خطا مربوط به زیرنویسهای انسانی است نه رونویسهای ماشینی.
API گفتار به نوشتار گوگل در واقع از دیکشنریهای سازگار با دامنه خارجی پشتیبانی میکند. این دیکشنریها میتوانند هجیهای صحیحی از اصطلاحات خاص یا نامهای مناسب را ارایه دهند. در آینده، لیست کامل خوانندگان و مجریان اخبار هر ایستگاه و همچنین نام چهرههای اصلی موجود در اخبار میتوانند به این دیکشنریها اضافه گردند تا اطمینان حاصل شود که املای نام آنها به درستی توسط API شناخته و نوشته میشود.
با جمع همه اینان، متوجه میشویم تشخیص گفتار خودکار طی چند سال گذشته به طرز چشمگیری بهبود یافته است. با مقایسه زیرنویسهای اخبار تلویزیونی که توسط انسان تولید شده در برابر رونوشتهای ماشینی که توسط API گفتار به نوشتار گوگل کلود تولید شده، متوجه میشویم که هر دو، تا 92% بایکدیگر مطابقت دارند (درصورتی که تبلیغات را لحاظ نکنیم). البته وفاداری رونوشت ماشینی به مراتب بیش از زیرنویسهای انسانی است.
سخن آخر
در حقیقت، ماشین گوی سبقت را در همه ابعاد از زیرنویسهای انسانی میرباید؛ علت را میتوان در میزان خطای پایینتر، عدم اشتباهات تایپی، کیفیت بهتر، بزرگنویسی صحیح حروف جستوجو کرد. درحالیکه برای انجام این آزمایشها هیچ سفارشیسازی از API گوگل صورت نگرفته و تنها از یک فرهنگ واژه ساده برای هجی صحیح نامهای رایج در هر ایستگاه و نامهای اصلی در اخبار برای برطرف کردن خطاهای باقیمانده، استفاده شده است.
با همه اینها، رونوشتهای ماشینی مانند گفتار به نوشتار گوگل کلود هنوز حاوی خطاهایی هستند، اما اکنون در مرحلهای هستیم که رونوشتهای خودکار میتوانند با دقت بسیار بالا با زیرنویسهای انسانی در زمان واقعی برای محتوای اخبار تلویزیون رقابت کنند. در آینده و با ادامه پیشرفت این مدلها، رونوشت ماشینی بسیار دقیقتر و قابلاعتمادتر از زیرنویسهای انسانی خواهند شد.
در خاتمه باید این چنین بگوییم که گرافهای نشان داده شده در بالا، انقلاب هوش مصنوعی را نشان میدهند.