یادگیری نظارت شده یا یادگیری با ناظر یک سیستم یادگیری مدرن است که به ایجاد تغییر در شرکتها و صنایع کمک میکند. در این مطلب در مورد ماهیت، انواع الگوریتمها، مزایا و معایب یادگیری تحت نظارت اطلاعاتی ارائه کردهایم.
یادگیری نظارت شده چیست؟
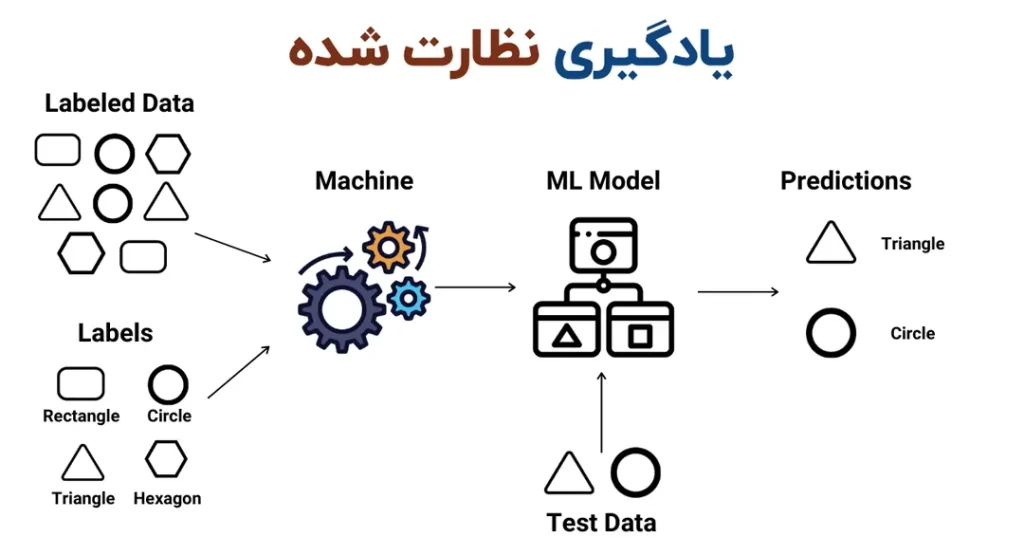
در یادگیری نظارت شده (Supervised Learning) به عنوان یکی از روشهای آموزش به ماشین، از دادههای برچسبدار استفاده میشود. این دادهها با ارائه به مدلِ در حال یادگیری برای پیش بینی نتایج یا تشخیص الگوها استفاده میشوند. در دادههای برچسب دار، خروجی مورد انتظار مشخص میشود. در این روش، مجموعهای از دادهها شامل ورودیها (features) و خروجیهای مطلوب (labels یا target) به مدل داده میشوند. هدف مدل، یادگیری رابطه بین ورودیها و خروجیها است. پس از آموزش، مدل میتواند برای پیش بینی خروجیهای جدید بر اساس دادههای جدید و فاقد برچسب استفاده شود. بر خلاف یادگیری بدون نظارت، الگوریتمهای یادگیری نظارت شده برای یادگیری رابطه بین ورودی و خروجیها برچسبگذاری میشوند.
الگوریتمهای یادگیری ماشین نظارت شده، ساخت مدلهای پیچیده برای سازمانها را آسانتر میکنند. این مدلها میتوانند پیش بینیهای دقیق انجام دهند. از این مدلها به طور گسترده در صنایع و زمینههای مختلف استفاده میشود. از جمله این زمینهها میتوان به مراقبتهای بهداشتی، بازاریابی، خدمات مالی و غیره اشاره نمود.
انواع الگوریتمهای یادگیری تحت نظارت
انواع مختلفی از الگوریتمها و روشهای محاسباتی در فرآیند یادگیری نظارت شده استفاده میشوند.
1. رگرسیون
رگرسیون برای درک رابطه بین متغیرهای وابسته و مستقل است. همچنین، نوعی از یادگیری نظارت شده است که از مجموعه دادههای برچسبدار استفاده میکند تا خروجیهای پیوسته را برای دادههای مختلف در یک الگوریتم تولید کند. این روش در موقعیتهایی که خروجی باید یک مقدار محدود داشته باشند، مانند قد یا وزن، به طور گسترده مورد استفاده قرار میگیرد. دو نوع رگرسیون وجود دارد:
- رگرسیون خطی: این الگوریتم برای شناسایی رابطه بین دو متغیر استفاده میشود و معمولا برای پیش بینیهای آینده به کار میرود. به طور دقیقتر، رگرسیون خطی بر اساس تعداد متغیرهای «مستقل» و «وابسته» قابل تقسیم بندی است. به عنوان مثال، اگر یک متغیر مستقل و یک متغیر وابسته وجود داشته باشد به آن «رگرسیون خطی ساده» گفته میشود. در حالی که اگر دو یا چند متغیر مستقل و وابسته وجود داشته باشد، به آن «رگرسیون خطی چندگانه» گفته میشود.
- رگرسیون لجستیک: از این رگرسیون زمانی که متغیر وابسته یک مقدار دستهای (Categorical) یا دودویی مانند «بله» و «خیر» دارد، استفاده میشود. همچنین، رگرسیون لجستیک برای حل مسائل دسته بندی دودویی به کار میرود؛ بنابراین مقادیر گسسته را برای متغیرها پیش بینی میکند.
2. بیز ساده (Naive Bayes)
الگوریتم بیز ساده برای مجموعه دادههای بزرگ استفاده میشود. این روش بر این فرض اساسی کار میکند که هر ویژگی در الگوریتم به طور مستقل عمل میکند؛ به این معنی که وجود یک ویژگی بر ویژگی دیگر تاثیر نمیگذارد. مدلهای مختلفی از بیز ساده وجود دارند و درخت تصمیم (Decision Tree) در میان سازمانهای تجاری محبوبترین مدل است. درخت تصمیم یک الگوریتم منحصر به فرد در یادگیری نظارت شده است که ساختاری شبیه به نمودار جریان (flowchart) دارد. با این حال، نقشها و مسئولیتهای متفاوتی را ایفا میکند.

درخت تصمیم شامل عبارات کنترلی است که شامل نتایج تصمیمات و پیامدهای حاصل از آنها است. خروجی در یک درخت تصمیم مربوط به برچسب گذاری دادههای غیرقابل پیش بینی است. الگوریتمهای ID3 و CART از الگوریتمهای محبوب درخت تصمیم هستند که در صنایع مختلف به طور گسترده استفاده میشوند.
3. دسته بندی (Classification)
این نوع از الگوریتم یادگیری نظارت شده، دادهها را به دقت در دستهها یا کلاسهای مختلف قرار میدهد. الگوریتمها موجودیتهای خاصی را شناسایی کرده و آنها را تحلیل میکنند تا متوجه شوند باید در کدام دسته قرار گیرند. برخی از الگوریتمهای دستهبندی عبارتند از:
- K-نزدیک ترین همسایهها (K-nearest neighbor)
- جنگل تصادفی (Random forest)
- ماشین بردار پشتیبان (Support vector machines)
- درخت تصمیم (Decision tree)
- طبقه بندهای خطی (Linear classifiers)
4. شبکههای عصبی (Neural Networks)
این نوع الگوریتم یادگیری نظارت شده برای گروه بندی یا دسته بندی دادههای خام استفاده میشود. همچنین برای یافتن الگوها یا تفسیر دادههای حسی به کار میرود. با این حال، این الگوریتم به منابع محاسباتی زیادی نیاز دارد و به همین دلیل به صورت محدود از آن استفاده میشود.
مزایا یادگیری تحت نظارت
- دقت بالا: دقتِ مدلهای آموزش داده شده به واسطه یادگیری نظارت شده برای تولید پیش بینیها بسیار زیاد است.
- تفسیر آسان: بسیاری از الگوریتمهای نظارت شده، مانند رگرسیون خطی آسان هستند و میتوانند نتایج را به شکل مفهومی توضیح دهند.
- قابلیت پیش بینی: به کمک دادههای جدید مدل میتواند پیشبینیهای دقیقی داشته باشد.
- کاربرد گسترده: این روش در طیف وسیعی از مسائل مانند پیش بینی بازار، تشخیص بیماری و تحلیل دادههای مالی استفاده میشود.

معایب و چالشهای استفاده از یادگیری تحت نظارت
- نیاز به دادههای برچسبدار: جمعآوری و برچسبگذاری دادهها زمانبر و هزینهبر است.
- خطر بیشبرازش (Overfitting): اگر مدل به خوبی تنظیم نشود، ممکن است نتایج خوبی روی دادههای آموزش نشان دهد ولی عملکرد ضعیفی روی دادههای جدید داشته باشد.
- محدودیت در پردازش دادههای پیچیده: برخی الگوریتمهای ساده ممکن است نتوانند الگوهای پیچیده را شناسایی کنند.
- نیاز به تنظیم پارامترها: بسیاری از الگوریتمها نیاز به تنظیم پارامترهای مختلف دارند تا بهترین عملکرد را داشته باشند، که این امر میتواند چالشبرانگیز باشد.
مثالی از یادگیری با نظارت
فرض کنید میخواهید یک مدل بسازید که قیمت خانهها را پیش بینی کند. برای این کار دادههایی شامل ویژگیهای مختلف خانهها (مانند: مساحت، تعداد اتاقها، سن ساختمان) و قیمت واقعی خانهها (برچسب) در دست دارید. مدل با استفاده از این دادهها آموزش داده میشود و رابطه بین ویژگیهای خانه و قیمت آن را یاد میگیرد. پس از آموزش، مدل قادر خواهد بود قیمت خانههای جدید را با استفاده از ویژگیهای مشابه پیش بینی کند.