


روش محاسباتی برای غربالگری ترکیبات دارویی میتواند پیش بینی کند که کدام ترکیبات دارویی در برابر سل یا سایر بیماریها بهترین عملکرد را دارند.
کاربرد یادگیری ماشین در کشف دارو
یادگیری ماشین یک ابزار محاسباتی است. این ابزار توسط بسیاری از زیست شناسان برای تجزیه و تحلیل مقدار زیادی از دادهها به آنها کمک میکند. با این ابزار میتوان داروهای جدید بالقوه را شناسایی کرد. محققان MIT اکنون ویژگی جدیدی را در این نوع الگوریتمهای یادگیری ماشین گنجاندهاند. این ویژگی توانایی پیش بینی این الگوریتمها را بهبود میبخشد.

این رویکرد جدید به مدلهای کامپیوتری اجازه میدهد تا عدم اطمینان را در دادههای تحلیلی خود حساب کنند. با استفاده از این رویکرد، تیم MIT چندین ترکیب امیدوار کننده را که پروتئین مورد نیاز باکتریهای عامل سل را مورد هدف قرار میدهند، شناسایی کردند.
دیدگاه محققین در مورد رویکرد بیان شده
بونی برگر، استاد ریاضیات سیمونز و رئیس گروه محاسبات و زیست شناسی می گوید: این روش که قبلاً توسط دانشمندان علوم رایانه استفاده میشد اما در زیست شناسی نتیجهای نداده بود، میتواند در طراحی پروتئین و بسیاری از زمینههای دیگر زیست شناسی نیز مفید واقع شود.
برگر می گوید: “این روش بخشی از زیرشاخههای شناخته شده یادگیری ماشین است. اما مردم آن را به زیست شناسی مربوط ندیدهاند. این یک تغییر پارادایم است. یک نحوه اکتشاف بیولوژیکی است”. برگر و برایان برایسون ، استادیار مهندسی بیولوژیک در MIT و عضو موسسه راگون MGH ،MIT و هاروارد، نویسندگان ارشد این مطالعه که امروز در سیستمهای سلولی ظاهر می شود، هستند. برایان هی، دانشجوی کارشناسی ارشد MIT ، نویسنده اصلی مقاله است.
ایجاد پیشبینیهای بهتر
یادگیری ماشین نوعی مدل سازی رایانه ای است. در یادگیری ماشین، یک الگوریتم یاد می گیرد بر اساس دادههایی که قبلاً دیده است، دادههای بعدی را پیشبینی کند. در سالهای اخیر، زیست شناسان شروع به استفاده از یادگیری ماشینی کرده اند. آنها پایگاه دادههای عظیمی از ترکیبات دارویی بالقوه را پیدا کردند. هدف آنها یافتن مولکولهایی با تعامل خاص است.

محدودیتهای الگوریتم ایجاد شده
این روش مانند هر روش دیگر نیز محدودیتهایی دارد. این الگوریتم زمانی که با دادههای مشابه با دادههای قبلی سر و کار دارد عملکرد خوبی دارد. اما در ارزیابی ملکولهای متفاوت از نمونههای قبلی، مهارت چندانی ندارد.
حل این محدودیت
برای غلبه بر آن ، محققان از تکنیکی به نام فرایند Gaussian استفاده کردند. این تکنیک عددی را بر حسب عدم اطمینان به دادههایی که الگوریتمها بر روی آنها آموزش داده شدهاند، اختصاص میدهد. به این ترتیب ، وقتی مدلها دادههای آموزش را تجزیه و تحلیل می کنند، میزان اطمینان این پیش بینیها را نیز در نظر می گیرند.
به عنوان مثال، اگر دادههای وارد شده به مدل پیش بینی کند که یک مولکول خاص چگونه به پروتئین هدف متصل می شود و همچنین عدم قطعیت پیش بینیها را مشخص کند. مدل می تواند با استفاده از این اطلاعات پیش بینی فعل و انفعالات پروتئین و هدف را انجام دهد.
قبلا دیده شده، این مدل همچنین قطعیت پیش بینیهای خود را تخمین می زند. هنگام تجزیه و تحلیل دادههای جدید، پیش بینیهای مدل ممکن است برای مولکولهایی که بسیار متفاوت از دادههای آموزشی هستند، اطمینان کمتری داشته باشند. محققان می توانند از این اطلاعات برای کمک به آنها در تصمیم گیری در مورد آزمایش مولکولهای آزمایشی استفاده کنند.

مزیت این روش
مزیت دیگر این روش این است که الگوریتم فقط به مقدار کمی از دادههای آموزشی نیاز دارد. در این مطالعه، تیم MIT این مدل را با مجموعه ای از 72 مولکول کوچک و فعل و انفعالات آنها با بیش از 400 پروتئین به نام پروتئین کیناز ، آموزش داده است.
سپس آنها توانستند با استفاده از این الگوریتم تقریباً 11000 مولکول کوچک را که از پایگاه داده ZINC ، مخزنی در دسترس عموم حاوی میلیون ها ترکیب شیمیایی، تجزیه و تحلیل کنند. بسیاری از این مولکول ها بسیار متفاوت از دادههای آموزش بودند.
با استفاده از این رویکرد، محققان توانستند مولکولهایی را با میلیونها اتصال پیش بینی شده بسیار قوی برای پروتئین کینازهایی که در مدل قرار می دهند شناسایی کنند.
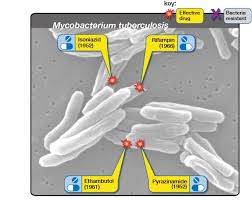
این شامل سه کیناز انسانی، و همچنین یک کیناز موجود در مایکوباکتریوم سل است. آن کیناز، PknB ، برای زنده ماندن باکتریها حیاتی است. اما توسط آنتی بیوتیکهای سل هدف قرار نمیگیرد.
بررسیهای محققین
محققان سپس برخی از بهترین بازدیدهای آنها را به صورت آزمایشی بررسی کردند تا ببینند در واقع چقدر به هدف نزدیک هستند. دریافتند که پیش بینیهای این مدل بسیار دقیق بوده است.
در بین مولکولهایی که این مدل بالاترین اطمینان را به خود اختصاص داده است، حدود 90 درصد موفقیت واقعی را نشان می دهد. بسیار بالاتر از میزان موفقیت 30 تا 40 درصدی مدلهای یادگیری ماشین موجود که برای صفحههای دارویی استفاده می شود، است.
محققان همچنین از همان دادههای آموزشی برای آموزش یک الگوریتم سنتی یادگیری ماشین استفاده کردند. این روند عدم قطعیت را در بر نمی گیرد. سپس به تجزیه و تحلیل همان کتابخانه 11000 مولکولی پرداختند.
برایان هی می گوید: “بدون عدم اطمینان، مدل به طرز وحشتناکی درگیر می شود. ساختارهای شیمیایی بسیار عجیبی را به عنوان برهم کنش با کینازها پیشنهاد می کند”.
محققان سپس امیدوار کننده ترین مهارکنندههای PknB خود را گرفته. آنها را در برابر مایکوباکتریوم توبرکلوزیس رشد یافته در محیط کشت باکتری آزمایش کردند. دریافتند که رشد باکتریها را مهار می کنند. این بازدارندهها همچنین در سلولهای ایمنی بدن انسان آلوده به این باکتری کار می کنند.
یک نقطه شروع خوب
یکی دیگر از عناصر مهم این روش این است که محققان به محض دریافت دادههای آزمایشی اضافی، می توانند آن را به مدل اضافه کرده و مجدداً آموزش دهند. پیش بینیها را بیشتر بهبود ببخشند.
محققان می گویند، حتی مقدار کمی از دادهها می تواند به بهتر شدن مدل کمک کند.
برایان هی می گوید: “شما واقعاً به مجموعه دادههای خیلی بزرگ در هر تکرار احتیاج ندارید.” “شما فقط می توانید با استفاده از 10 مثال جدید مدل را دوباره آموزش دهید. چیزی که یک زیست شناس می تواند به راحتی تولید کند”.
برایسون می گوید: این مطالعه اولین تحقیق در طی سالهای متمادی است که مولکولهای جدیدی را پیشنهاد می کند که می توانند PknB را هدف قرار دهند. این روند برای تولیدکنندگان دارو شروع خوبی برای تلاش برای تولید داروهایی باشد که کیناز را هدف قرار می دهند، است.
او می گوید: “ما در حال حاضر چند راهنمای جدید فراتر از آنچه در گذشته منتشر شده است، به آنها ارائه داده ایم”.
محققان همچنین نشان دادند که آنها میتوانند از همین نوع یادگیری ماشین برای افزایش تولید فلورسنت یک پروتئین فلورسنت سبز استفاده کنند. که معمولاً برای برچسب زدن مولکولهای داخل سلولهای زنده استفاده می شود.
برگر می گوید، این روش همچنین میتواند در انواع مختلفی از مطالعات بیولوژیکی اعمال شود. که اکنون از آن برای تجزیه و تحلیل جهشهایی که رشد تومور را تحریک می کنند، استفاده میکند.
بودجه تحقیق توسط وزارت دفاع ایالات متحده از طریق بورس تحصیلی فارغ التحصیلان علوم و مهندسی دفاع ملی تأمین شد. موسسات ملی بهداشت ؛ موسسه راگون MGH ، MIT و هاروارد و گروه مهندسی بیولوژی MIT.