


یادگیری ماشین و هوش مصنوعی فرصتهای بسیار زیادی را برای بهبود فرآیندهای کسب و کارها ایجاد کرده اند و باعث شدهاند که هر کسب و کاری برای به حداکثر رسیدن درآمدش به هوش مصنوعی روی بیاورد. هوش مصنوعی روز به روز در حال پیشرفت و ایجاد نوآوریهای جدید است. الگوریتم هوش مصنوعی برای هر کسب و کاری متفاوت است و نیازهای مختلفی را برطرف میکنند. شاید بتوان گفت در حال حاضر هزاران الگوریتم هوش مصنوعی در دنیا ایجاد شده است. ما در این مقاله میخواهیم به معرفی 5 الگوریتم هوش مصنوعی بپردازیم که شاید نسبت به بقیه نامشان بیشتر شنیده شده باشند. پس اگر به این موضوع علاقمندید در ادامه با ما همراه باشید.
رگرسیون خطی
رگرسیون خطی بیش از 200 سال است که در آمار ریاضی استفاده می شود. نکته مهم در این الگوریتم، یافتن چنین مقادیر ضرایب (B) است که بیشترین تأثیر را روی دقت عملکردی f، که مدلی است که می خواهیم آموزش دهیم، فراهم می کند. ساده ترین مثال آن به شرح زیر است:
y = B0 + B1 * x
جایی که B0 + B1 عملکرد مورد نظر ما است.
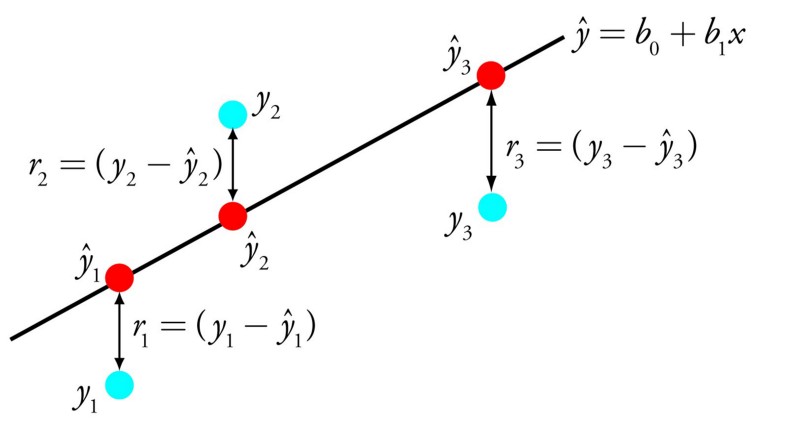
با تنظیم وزن این ضرایب ، دانشمندان داده نتایج متفاوتی از آموزش دریافت میکنند. نیاز اصلی برای موفقیت در این الگوریتم داشتن داده های واضح و بدون شلوغی زیاد (یا اطلاعات کم ارزش) در آن و حذف متغیرهای ورودی با مقادیر مشابه (مقادیر ورودی همبسته) است. این مسئله با استفاده از الگوریتم رگرسیون خطی برای بهینه سازی نزولی شیب دادههای آماری برای استفاده در امور مالی، بانکی، بیمه، مراقبت های بهداشتی، بازاریابی و سایر صنایع امکان پذیر است.
رگرسیون لجستیک
رگرسیون لجستیک یکی دیگر از الگوریتم های محبوب هوش مصنوعی است که قادر به ارائه نتایج باینری (یا همان دو-دویی) است. این بدان معنی است که مدل می تواند هر دو نتیجه را پیش بینی کند و یکی از دو کلاس از مقدار y را مشخص کند. این تابع همچنین بر اساس تغییر وزن الگوریتم ها تنظیم میشود، اما به دلیل این مسئله که از عملکرد منطق غیر خطی برای تغییر نتیجه استفاده می شود، متفاوت است. این تابع می تواند به عنوان یک خط S شکل، مقادیر واقعی را از مقادیر کاذب جدا کند.

الزامات موفقیت این الگوریتم همانند رگرسیون خطی است (یعنی از بین بردن نمونه های ورودی با ارزش مشابه و کاهش مقدار نویز یا همان داده های کم ارزش).
درخت تصمیم گیری
شاید بتوان گفت این الگوریتم یکی از قدیمی ترین، پرکاربردترین، ساده ترین و کارآمدترین مدل یادگیری ماشین و هوش مصنوعی در دنیا است. این الگوریتم در واقع یک درخت باینری کلاسیک است که دارای دو نوع تصمیم بله یا خیر در هر تقسیم است و تا رسیدن مدل به گره نتیجه گیری ادامه مییابد. یادگیری در این مدل بسیار ساده است و نیازی به عادی سازی دادهها ندارد. این الگوریتم میتواند به حل انواع مختلفی از مشکلات کمک کند.
K- نزدیکترین همسایگی
این الگوریتم یک مدل یادگیری ماشین بسیار ساده ودر عین حال بسیار قدرتمند است که از کل مجموعه دادههای آموزشی به عنوان قسمتی از نمایندگی استفاده میکند. در این الگوریتم پیش بینیهای مقدار نتیجه با بررسی کل مجموعه داده ها برای گره های داده K با مقادیر مشابه (یا به اصطلاح همسایه) و استفاده از عدد اقلیدسی (که می توان به راحتی براساس اختلاف مقادیر محاسبه شد) محاسبه می شود تا مقدار نهایی را تعیین کند.
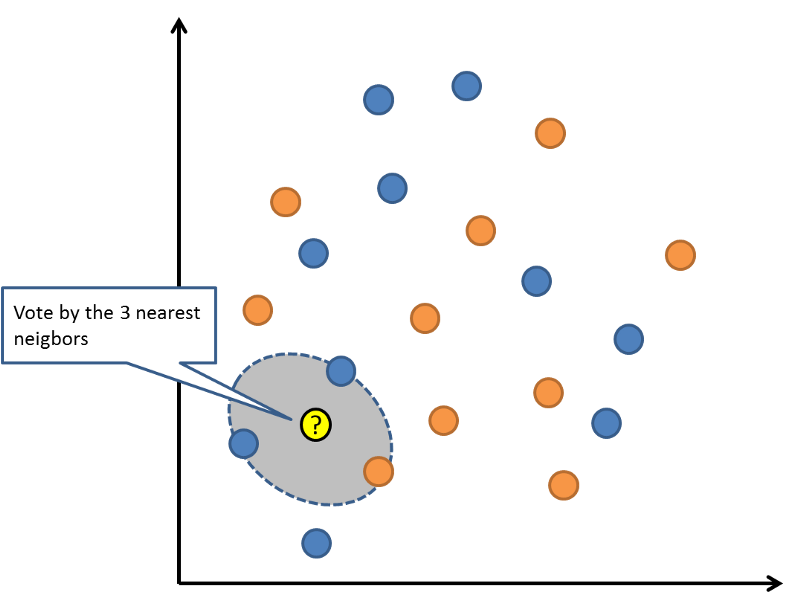
چنین دیتاستی برای ذخیره سازی و یا پردازش داده ها به منابع محاسباتی زیادی احتیاج دارد، در صورتی که صفات متعددی وجود داشته باشند، باعث کاهش یا از بین رفتن دقت می شود. با این حال، این الگوریتم بسیار سریع کار می کند، دقیق بسیار بالایی دارد و برای پیدا کردن مقادیر مورد نیاز در دیتاستهای بزرگ بسیار کارآمد هستند.
ماشین های بردار پشتیبان
الگوریتم ماشین بردار پشتیبان یکی از گسترده ترین بحثها در بین دانشمندان داده است، زیرا قابلیتهای بسیار قدرتمندی را برای طبقه بندی داده فراهم می کند. به اصطلاح هایپرلین خطی است که گره های ورودی داده را با مقادیر مختلف از هم جدا می کند و بردارها از این نقاط به هایپرپلان میرسند که می توانند از آن پشتیبانی کنند (وقتی همه نمونه های داده از یک کلاس در همان سمت هایپرپلان قرار دارند) یا با آن مخالفت کنند (هنگامی که نقطه داده خارج از صفحه کلاس خود است).
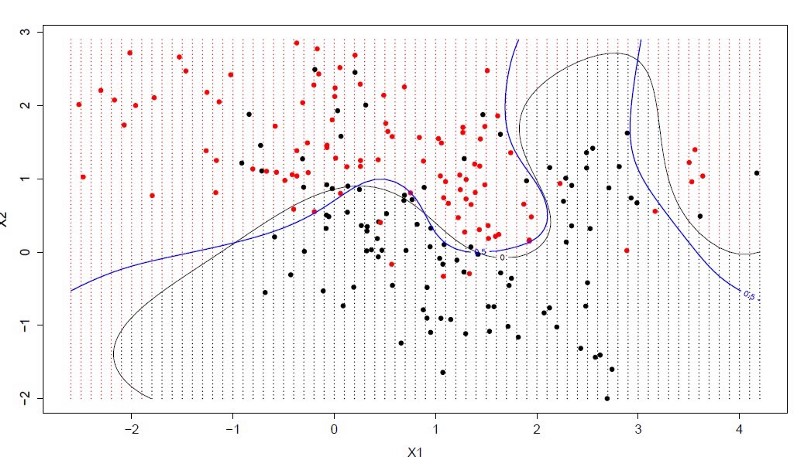
بهترین هایپرپلین یکی از بزرگترین بردارهای مثبت و با توانایی جدا کردن بیشترین گره های داده خواهد بود. این الگوریتم یک ماشین طبقه بندی بسیار قدرتمند است که می تواند برای طیف گسترده ای از مشکلات و عادی سازی داده ها اعمال شود.
برای مطالعه بیشتر در زمینه هوش مصنوعی و کاربردهای آن به بلاگ عامر اندیش مراجعه کنید.
2 پاسخ
مگه اینا الگوریتم هستند؟ اینها مربوط به یادگیری ماشین هستند و در حقیقت ابزار هستند نه الگوریتم. الگوریتمهای هوش مصنوعی برای بهینه سازی کاربرد دارند.
سلام اینها واقعا الگوریتم هستند.
مثلا توی گوگل بنویسه k nearest neighbor اولین پیشنهادی که نمایش داده میشه با واژه algorithm آورده شده