


مهمان قسمت پنجم پادکست باهوش: حمید روحانی
با هوش برنامه ای با موضوع کاربرد هوش مصنوعی در کسب و کارها است که به کمک شرکت عامر اندیش و با اجرای رسول محمدی تولید شده است. هدف این برنامه افزایش آگاهی در زمینه کاربردهای هوش مصنوعی در کسب و کارها و راه حل های موجود در این حوزه است. در طی قسمت های مختلف مصاحبه هایی با متخصصین و مدیران محصولات مبتنی بر هوش مصنوعی صورت گرفته تا به شکلی کاربردی به چالش ها و راهکارهای موجود در این حوزه پرداخته شود.
اگر خاطرتان باشد در قسمت دوم راجع به مزیت های استفاده از هوش مصنوعی در مراکز تماس صحبت کردیم. در آن برنامه رضا خیلی مختصر در مورد یکی از قابلیت های مهم هوش مصنوعی یعنی تبدیل گفتار به متن صحبت کرد. در این برنامه قصد داریم کمی بیشتر راجع به این فناوری صحبت کنیم و به همین خاطر رفتیم سراغ حمید روحانی مدیر فنی فارس آوا.
- درود بر دنبال کنندگان با هوش، من رسول محمدی، با قسمتی دیگر از این برنامه در خدمت شما عزیزان هستم. قصد ما در پادکست باهوش، افزایش آگاهی در زمینه کاربردهای هوش مصنوعی در کسب و کارها و راه حل های موجود در این حوزه است. سلام حمید جان، خیلی خوش آمدی.
- سلام رسول جان، خیلی ممنونم که من را به این برنامه دعوت کردی و سلام عرض می کنم خدمت شنوندگان عزیز.
- حمید مقاله ای میخواندم که آمارهای جالبی از فراگیر شدن جستجوهای مبتنی بر صدا داشت. مثلاً میگفت الان 20 درصد جستوجوهای گوگل از طریق voice انجام می شود و حدود 31 درصد از کاربرای دنیا حداقل هفته ای یک بار از تکنولوژی مربوط به voice استفاده میکنند. راست است که میگویند تا سال بعد نصف جست و جوهای آنلاین در دنیا بر اساس voice انجام میشود؟
- بله، این امر مسئلهی جالبی است. من میخواستم یک چیزی را یادآوری کنم. اگر یادتان باشد، قبلا امکان تشخیص گفتار در گوشیهای همراه نوکیا قدیمی وجود داشت به اسم speek to dial که از طریق آن کاربرها میتوانستند اسم مخاطبهای داخل دفترچهی مخاطبین گوشی را با صدا ضبط کنند و با گفتن اسم مخاطب بتوانند با او تماس برقرار کنند. در آن زمان میتوانستید 100 مخاطب را در سیم کارت ذخیره کنید و برای مثال زمانی که من میخواستم با تو تماس بگیرم میگفتم به همان شکلی که قبلا اسم رسول را برای ضبط کردن بیان کرده بودم، اسم تو را میگفتم و گوشی با تو تماس میگرفت. مشکل این مسئله آن بود که باید دقیقا با یک لحن میگفتی و یا اگر در فضای متفاوتی با زمانی که صدا را ضبط کردی قرار داشتی، دیگر نمیشد از این قابلیت استفاده کرد. در آن زمان به این قابلیت به صورت فانتزی نگاه میشد و مردم بعد از استفاده از آن کنارش میگذاشتند. شاید علتش آن بود که وجود این قابلیت مشکلی را برای افراد حل نمیکرد چون عملا در گوشیهای قدیمی زمان بیشتری صرف تایپ کردن پیامک میشد اما پیدا کردن یک مخاطب و تماس با او زمان بسیار کمی را میطلبید. قابلیت تبدیل گفتار به نوشتار امروز برای کاربران کاربردیتر است زیرا که میتوانند متنی را که میخواهند تایپ کنند را تنها با خواندنش به متن تبدیل نمایند و این امر بسیار کاربردیتر از تنها تماس گرفتن با یک فردی است. ضمن اینکه آن قابلیت بسیار ساده بود و فقط مقایسه دو سیگنال با یکدیگر بود، سیگنالی که قبلا ضبط کرده بودید و سیگنالی که قرار است بعدا از آن درخواست کنید و در عمل تنها میتوانست به مخاطب زنگ بزند اما متنی به شما نمیداد. در مقابل امروزه در محصولاتی مانند اسپیکرهای هوشمند، هیچ رابط کاربری غیر از رابط صوتی وجود ندارد و تنها با صوت ارتباط برقرار میکند.
- یعنی دستوری میدهی که متن آن را نداری؟
- هم دستور میگیرد و هم خیلی کارهای دیگری را انجام میدهد. برای مثال هم با کسی تماس بگیرد هم زمان آلارم را برای شما تنمظیم کند، قراری که دارید را برای شما برنامه ریزی کند، در اینترنت جست و جو کند یا چراغهای خانه شما را روشن و خاموش کند و … و تمام اینها تنها به وسیله صدا انجام میشود. علاوه بر آنکه الان پیشرفت این فناوری به حدی رسیده که اسپیکرهای هوشمند تنها میتوانند با صدای کسی که در سامانه آن اسپیکر ثبت نام کرده است کار کنند.
- می شود کمی فنی این مسئله را توضیح دهی و بگویی که اصلاً Speech to text یا همان تبدیل گفتار به نوشتار چگونه عمل میکند؟
- توضیح سادهاش آن است که شما یک سیگنال صوتی دارید و این سیگنال را از گوینده دریافت میکنید و میخواهید متن متناظر با آن را بدست بیاورید. قبلا اینگونه بود که یک سیگنال مرجع را با سیگنال نمونه مقایسه میکردند و سپس مقایسه بین سیگنالی یا signal processing انجام میشد. وجود نویز در این قضیه خیلی تاثیرگذار بود و حساسیت زیادی به آن داشت. اما الان روشهایی بر پایه طبقه بندی و شناسایی الگو و یادگیری ماشین وجود دارند که اثر نویز را بشدت کاهش میدهند و باعث افزایش دقت میشوند. اما این روشها نیازمند آن است که یک مجموعه داده بزرگ و با کیفیت برای آموزش داشته باشیم. سیستمهای تبدیل گفتار به نوشتار یک سیگنال را دریافت میکنند و به نوعی بازنمایی (representation) صوتی تبدیل میکنند تا بتواند روی آن پردازش انجام دهند. روی این سیگنالی که بدست میآید یکسری پیش پردازشهایی انجام میشود، مثلا حذف نویز و یا تشخیص سکوت و نقاط توقف که گوینده در صحبتش دارد، و در نهایت از هرکدام از این تکه صوتهایی که بدست میآید یکسری ویژگی قابل پردازش توسط سیستم تبدیل گفتار به متن استخراج میشود. سپس از بازنمایی صوتی که داشتیم محتملترین واحد صوتی کوچک و معتبر، برای مثال آواهایی که در زبان فارسی داریم، بدست میآورد و به مرحله بعدی میرود. تا به اینجا، این کار توسط یک مدل آکوستیک یا آوایی انجام میشد و در واقع آن مدل آوایی مدل ورودی را به یک بازنمایی آوایی تبدیل میکند. بعد از آن از خروجی قسمت آوایی محتملترین دنباله زبانی را، در همان زبان مورد نظر، را استخراج میکنند. به این قسمت دوم مدل زبانی گفته میشود. یعنی عملا ما دو قسمت داریم، مدل آوایی و مدل زبانی. خروجی مدل زبانی همان نتیجه متنی است که شما از گفتار اولیه بدست میآورید.

- آیا کلمات و جملات محاوره ای هم در این سیستم قابل درک است و یا اینکه حتماً باید به صورت کتابی صحبت کنیم تا صحبتهای ما به متن تبدیل شود؟ تو از یکسری احتمالات زبانی صحبت کردی، آیا در زبان محاوره نیز این موضوع صدق میکند؟
- بله به این قضیه که اشاره کردی تنوع گفتاری گفته میشود. به این مسئله تنوع گفتاری محاوره و معیار گفته میشود. در گفتار محاوره به دلیل آن که برخی از کلمات خارج از دایره واژگان نوشتاری هستند، مقداری متفاوتتر از معیار میباشد. مسئله دیگر آن است که کلمات طوری تلفظ میشوند که گوینده راحتتر و سریعتر باشد و حتی آواهایی داریم که ممکن است قابل نوشتن نباشند. در کل به این صورت است که تنوع گفتاری را میتوان با مجموعه داده ورودی که به سیستم آموزش میدهید حل کنید. یعنی مجموعه داده ورودی شما محاورهای باشد. اما خوب این مسئله هم باعث میشود تا خطاهایی پیش بیاید. در تنوعی که به آن اشاره کردم گونه دیگری نیز وجود دارد که به آن گفتار گسسته و گفتار پیوسته گفته میشود. گفتار پیوسته به این صورت است که فرد در بین کلماتش هیچ سکوت قابل تشخیصی نیست. زمانی که فرد به صورت پیوسته صحبت میکند تشخیص آن مقداری مشکل میشود و بالتبع تشخیص گفتار گسسته آسانتر است. به همین نسبت که گفتار پیوسته سختتر از گفتار گسسته است، گفتار محاوره را نیز سختتر از گفتار معیار میتوان تشخیص داد.
- میدانم که گوگل الان خیلی خوب در این زمینه دارد کار میکند و تقریباً توانسته در همهی زبان ها (اگر اشتباه نکنم 120 زبان) محصول تبدیل گفتار به نوشتار خود را عرضه کند. در زبان فارسی به جز گوگل آیا شرکت دیگری هم وارد شده است؟
- گوگل در زمینه پردازش زبان طبیعی تقریبا در همهی بخشهایش بسیار فعال عمل کرده است و خیلی با جدیت به آن عمل میکند و سرمایهگذاری زیادی روی این مبحث انجام داده است. شرکتهای دیگری هم هستند که روی زبان فارسی کار میکنند اما سرمایهگذاری گوگل روی این قضیه بسیار زیاد است. به همین دلیل برای بسیاری از شرکتها عملا به صرفه است که سرویسی را از گوگل بگیرند و همان را با تغییرات محدودی به کاربران ارائه دهند و بدین صورت خود را درگیر جمع کردن دادههای بسیار زیاد و پر هزینه و هم چنین پیچیدگی کار نیز نکنند. اما در شرکت ما به جای آنکه از سرویس آماده گوگل استفاده شود در این چند سال چندین هزار ساعت داده با کیفیت جمع کردهایم و توانستیم با استفاده از آن داده اولیه و آموزش سیستمهایمان یک سرویس تبدیل گفتار به متن بومی تولید کنیم. بدون اینکه از اول برای استفاده از آن اول یعنی آموزش سیستم تا آخر یعنی ارائه به کاربر، بدون اینکه از اول یعنی آموزش سیستم تا آخر یعنی ارائه به کاربر، نیاز باشد که به اینترنت دسترسی داشته باشیم یا به شرکت دیگری وابسته باشیم، سرویس خود را به کسب و کارها و کسانی که به تبدیل گفتار به نوشتار نیاز دارند ارائه دهیم.
- فکر میکنم سرویس گوگل که در اندروید رایگان است و خیلی از کسب و کارها میتوانند از آن استفاده کنند. به نظرت چرا یک کسب و کار باید حاضر شود که از سرویس گوگل چشمپوشی کند و از سرویس های مشابه داخلی که رایگان نیستند استفاده کند؟
- مسئلهای که وجود دارد آن است که در زبان ما تنوع لهجه و گویش زیادی وجود دارد و پوشش دادن این لهجهها و گویشها نیازمند آن است که هم شناخت درستی از زبان داشته باشیم و هم بتوانیم به صورت مداوم سیستم را آموزش دهیم و آن لهجهها را به سیستم اضافه کنیم. علاوه بر این قضیه یکسری کلمات خاص برای مثال کلماتی مربوط به کسبوکارهای خاصی وجود دارند که باید آنها را نیز به سیستم عام تشخیص گفتار و تشخیص نوشتار از گفتار . این مسئله در محصول گوگل وجود ندارد و در آن یک سیستم خیلی عام دارید که صرفا میتواند گفتار عام را تشخیص دهد و به نوشتار تبدیل کند. برای مثال سیستمی که گفتی روی اندروید، باید توجه داشت که سرویس گوگل با اپلیکیشن آن متفاوت است. اپلیکیشن گوگل که تو به آن اشاره کردی Google Keyboard است که رایگان میباشد و شما میتوانید به صورت رایگان بر روی ios و اندروید استفاده کنید. اما این اپلیکیشن در حقیقت از سرویس گوگل استفاده میکند که آن سرویس رایگان نیست.
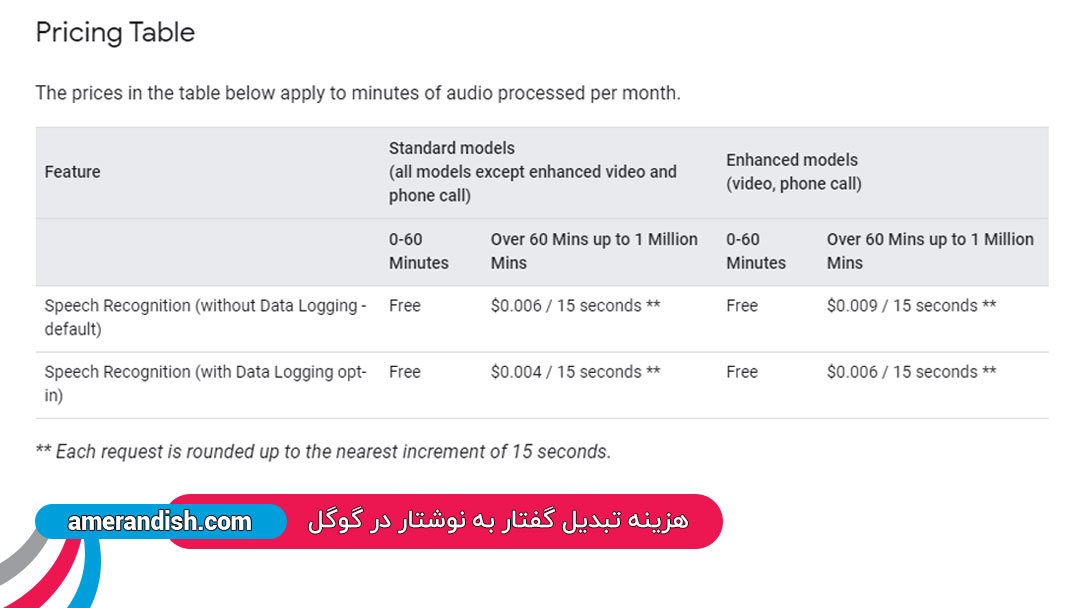
- یعنی یک اپلیکیشن اگر بخواهد از سیستم گوگل استفاده کند باید پول پرداخت کند؟
- بله، به ازای هر ثانیه و یا دقیقهای که استفاده میکنیم به همان میزان باید پول بدهیم. دیگر اینکه نوع آن نیز تفاوت دارد. یعنی اگر ذخیره شود هزینهی متفاوتی دارد با زمانی که ذخیره نشود و … . پس اولا سرویس گوگل رایگان نیست و بعد اینکه ممکن است محدودیتهایی بوجود بیاید. برای مثال اپلیکیشن لنز گوگل عکس را میگیرد و تصاویر موجود در آن را استخراج میکند. این اپلیکیشن در اندروید کار میکند اما در iOS کار نمیکند. به این دلیل که ارائه این سرویس بر روی iOS فیلتر است. در این جا هم هر زمانی ممکن است گوگل سرویسش را قطع کند و دیگر نتوانید از آن استفاده کنید. برای مثال اگر یادتان باشد سرویس گوگل مپ حدود یک و نیم سال قبل برای سایتهایی که دامنه ir داشتند قطع شد و دلیلی که برای آن بیان شد عدم سازگاری با قوانین این سرویس بود. به همین دلیل اگر کسب و کارها میخواهند که سیستمی قابل اتکا را به کسب و کارشان اضافه کنند باید از سیستمی استفاده کنند که به آن اطمینان داشته باشند. چون اگر قرار است یک سیاست گذاری را انجام دهیم و با توجه به تفکراتی یک سیستمی را به کسب و کار و یا اپلیکیشن خود اضافه میکنیم باید از پایداری آن مطمئن باشیم و قرار نیست به هر دلیلی این سیستم قطع شود. مسئله دیگری هم که وجود دارد آن است که شاید یک کسب و کار دوست نداشته باشد که دادههایش به خارج از کشور و یا سازمانش فرستاده شود و به همین دلیل به یک سیستم لوکال نیاز دارد، همانند بانکها و … . در این موارد نمیتوان از سرویس گوگل استفاده کرد.
- در سوال قبلی داشتی در مورد واژگان تخصصی توضیح میدادی که اگر بخواهی کلمه تخصصی را وارد دایره واژگان کنی شاید کمی سخت باشد. میشود بیشتر در مورد این مسئله توضیح دهی؟ آیا هر کسب و کاری میتواند دایره واژگان تخصصی مجزا برای خودش تهیه کند؟ و اگر بله این کار چه مزیتهایی به همراه دارد؟
- این مسئله که گفتی جزء تنوعهای گفتار است یعنی جزء تنوع واژگان یک زبان قرار میگیرد. ممکن است یک کسب و کار فقط بخواهد از کاربرش جواب بله یا خیر بشنود و واژه دیگری را لازم ندارد.برای این قضیه نمیتوانید یک سیستم جامع را به آن کسب و کار ارائه دهید و به او بگویید که تنها از بله و خیر استفاده کن. به این دلیل که هم هزینه بیشتری را متقبل میشود و هم امکان دارد سرعت و دقت کاهش پیدا کند. برای مثال اگر لازم باشد شما سیستمی را آموزش دهید که تنها بله یا خیر را دریافت کند خیلی آسانتر است که از مجموعه مطلوبی آن کسب و کار مدل زبانی و آوایی استخراج کنید و به او ارائه دهید، در این صورت حتی بر روی سخت افزار کم هزینهتری هم میتواند اجرا شود.
- این مسئله فکر میکنم برای اپلیکیشنهای مسیریاب بسیار کاربردی باشد. برای مثال یک اپلیکیشن که کار نشان دادن مسیر را انجام میدهد که تنها اسم معابر را دریافت کند. درسته؟
- بله چون همین اسم معابر که گفتید یک مجموعه لغاتی است که عام نیستند و شاید بسیاری از آن استفاده نکنند.
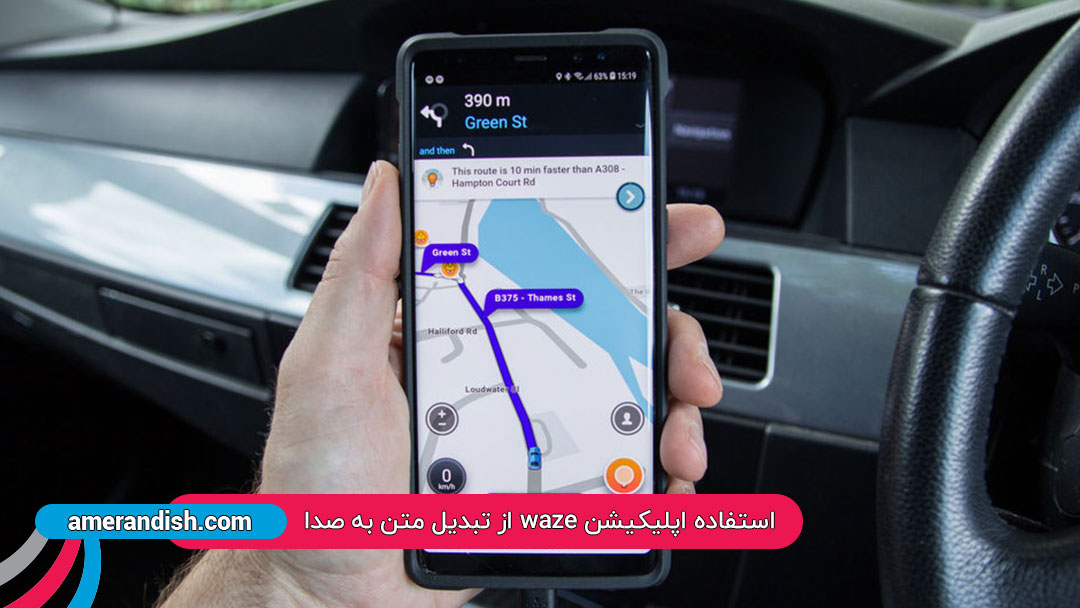
- برای همین است که waze اسامی معابر را با لهجه عجیبی بیان میکند؟
- بله ضبط کردن اسامی کوچه ها و دادن آن به سیستم که بعدا بتوانی از آن خروجی خاصی بگیری میتواند برای کسبوکارهای مختلف متفاوت باشد. و اینکه درست کردن سیستم جامعی که به همه جواب دهد ممکن نیست. به همین دلیل برای یک کسب و کار خاص، شما باید دادههای همان کسبوکار را داشته باشید و از آن به مدل مورد نظر برسید. مثال دیگری که میتوانم به آن اشاره کنم آن است که در برنامه قبل که با رضا ضبط کردی، راجع به تلفن صحبت کردی که به آن داده تلفنی گفته میشود که دادهای است که از رسانهی تلفن ضبط میشود. ما در اینجا با یک تنوع رسانهای مواجهیم یعنی اینکه صدای گوینده از چه رسانهای دریافت میشود و شما آن را با چه مشخصات و کیفیتی دریافت میکنید. تشخیص گفتار مسلما در رسانههای مختلف متفاوت است به این دلیل که ویژگیهایی که میتوانید از یک صدا دریافت کنید، با صدای دیگر در رسانهای دیگر متفاوت است.
- این هم قابل سفارشی سازی است؟
- این هم همینطور. میتوانید دادهای که به سیستم آموزش میدهید داده تلفنی باشد و آن سیستم در نهایت دادههای تلفنی را با دقت بالا تشخیص میدهد. اما ممکن است شما در رسانهی دیگر همان دقت را نداشته باشید.
- مرسی حمید که مهمان باهوش این قسمت ما بودی. امیدوارم باز هم اینجا بیای و بیشتر ما را با قابلیتهای هوش مصنوعی آشنا کنی. موضوعی بود که دوست داشتی راجع به آن صحبت کنی و من ازت نپرسیدم؟
- خیلی ممنون رسول جان. چیزی که من میخواستم بگم آن است که ما برای سرویسهایی که الان ارائه میدهیم قابلیت تست رایگان هم گذاشتهایم. میخواهم از کسبوکارها و توسعه دهندهها درخواست کنم اگر مایل هستند به سایت ما مراجعه کنند و سرویسهایمان را تست کنند که هم از کیفیت و هم از پایداری آن اطمینان داشته باشند و اگر تصمیم گرفتند که به کسبوکارهایشان این سرویس را اضافه کنند با خاطری آسوده این کار را انجام دهند. مسلما هزینهای که برای استفاده از سرویسهای ما بعد از اینکه تست را انجام دادند میپردازند خیلی کمتر از سرویسهای مشابه است و درخواست میکنم که اگر نقطه نظری وجود دارد یا ایرادی به چشمشان آمد، از طریق کانالهای ارتباطی آن را با ما در میان بگذارند.
- درود بر تو و همه دوستانی که با هوش شنیدند.
لینک کوتاه شده : https://amerandish.com/lvich


