


فریم ورک تشخیص شی Viola–Jones اولین فریم ورک تشخیص شی است که به نرخ رقابتی تشخیص شی در سال 2001 رسید. این فریم ورک توسط Paul Viola و Micheal Jones ارائه شد. اگر چه این فریم ورک میتواند برای انواع شیها آموزش داده شود، در درجه اول تمرکز این فریم ورک بر روی تشخیص چهره است. امروزه تشخیص چهره و تشخیص شی یکی از پرکاربردترین قابلیتهای هوش مصنوعی که به زندگی بشر بسیار کمک کرده است.
توضیح مسئله
مسئله ای که این فریم ورک به آن میپردازد تشخیص چهره در یک تصویر است. یک انسان میتواند به سادگی در یک تصویر چهره افراد را تشخیص دهد، اما یک کامپیوتر در تشخیص چهره محدودیتهایی دارد.
برای اینکه کار تشخیص چهره توسط کامپیوتر قابل مدیریت باشد، Viola-Jones نیازمند نمای کامل صورت از جلو است. بنابراین برای اینکه یک چهره تشخیص داده شود، کل صورت باید رو به دوربین باشد.
این محدودیت تا حدی از جذابیت این الگوریتم کم میکند، چرا که مرحله شناسایی، بعد از مرحله تشخیص است.
مولفههای فریم ورک
ارزیابی و انواع ویژگی
مشخصههای الگوریتم Viola-Jones که آن را به یک الگوریتم تشخیص خوب تبدیل کرده است عبارتند از:
- مقاومت- نرخ تشخیص بسیار بالا (نرخ مثبت حقیقی) و نرخ مثبت کاذب بسیار پایین.
- بلادرنگ بودن- حداقل دو فریم رو در هر ثانیه پردازش میکند.
- تنها تشخیص چهره (نه شناسایی چهره)- هدف تشخیص چهره از غیر چهره است (تشخیص مرحله ابتدایی فرآیند شناسایی است).
الگوریتم چهار مرحله دارد:
- انتخاب ویژگی Haar
- ایجاد یگ تصویر انتگرالی
- آموزش Adaboost
- دسته بندی کننده آبشاری (Cascading)
همه فریم ورکهای تشخیص شی یا چهره در کل دنیا مجموعهای از پیکسلهای تصویر در یک ناحیه مستطیلی شکل را در نظر میگیرند. به همین ترتیب، این فریم ورک مشابه با تابع Haar basis است. این تابع قبلا در حوزه پردازش تصویر استفاده شده است.
به هر حال، از آنجایی که بیشتر امکانات فریم ورک Viola-Jones بیشتر بر ناحیه مستطیلی متکی هستند، معمولا پیچیده ترند. شکل زیر چهار نوع ویژگی متفاوت استفاده شده در این فریم ورک را تشریح میکند. مقدار هر ویژگی مشخص برابر مجموع پیکسلها در مستطیلها منهای مجموع پیکسلها در مستطیل سایه خورده است. ویژگیهای مستطیلی در زمان مقایسه با گزینههایی چون فیلتر steerable ویژگی اصلی هستند. اگر چه به عمودی و افقی بودن حساس هستند، نتیجه حاصل چشمگیرتر است.
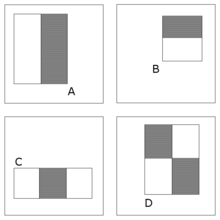
ویژگیهای Haar
همه چهرههای انسانی ویژگیهای مشابهی دارند. این موارد ممکن است با ویژگیهای Haar مطابقت داشته باشد. چند ویژگی متداول صورتهای انسان:
- ناحیه چشم از پیشانی تیرهتر است.
- روی بینی از ناحیه چشم روشنتر است.
با ترکیب ویژگیها، به ویژگیهای دیگری دست مییابیم:
- محل و انداز: چشمها، دهان، روی بینی.
- مقدار: گرادیان شدت پیکسلها.
چهار ویژگی منطبق با این الگوریتم در تصویر یک چهره دیده شده است. ویژگیهای مستطیل:
- مقدار= Σ (پیکسل در منطقه تاریک) – Σ (پیکسل در ناحیه سفید)
- سه نوع: دو، سه و چهار مستطیل، Viola & Jones از ویژگی دو مستطیلی استفاده کردند.
- برای مثال: تفاوت در روشنایی بین مستطیلهای سیاه و سفید در یک ناحیه خاص.
- هر ویژگی به یک ناحیه در زیر_پنجره مربوط است.
جدولبندی ناحیه
یک نمایش تصویر به نام تصویر انتگرالی ویژگیهای مستطیلی را در زمان ثابت ارزیابی میکند، که نسبت به موارد پیچیده تر مزیت سرعت عمل را دارد. هر ناحیه مستطیلی حداقل با یک مستطیل دیگر مجاور است. لذا هر ویژگی دو مستطیلی میتواند در شش ارجاع آرایه ای، هر ویژگی سه مستطیل در هشت، و هر ویژگی چهار مستطیل در نه ارجاع آرایه ای محاسبه شود.
الگوریتم یادگیری
سرعتی که با آن ویژگیها ممکن است ارزیابی شوند باعث نمیشود از تعداد بالای ویژگیها چشم پوشی کنیم. برای مثال، در یک زیرپنجره 24*24 پیکسل استاندارد، مجموعا M = 162,336 ویژگی ممکن وجود دارد، و ارزیابی همه آنها در زمان تست تصویر به شدت هزینه بر است. بنابراین، فریم ورک تشخیص شی از انواع الگوریتم یادگیری AdaBoost برای انتخاب بهترین ویژگیها و آموزش دسته بندی کننده برای استفاده از آنها استفاده کرده است. این الگوریتم یک دسته بندی کننده “قوی” به عنوان یک ترکیب خطی دسته بندی کننده “ضعیف” ساده است:
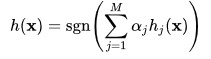
هر دسته بندی کننده ضعیف یک تابع آستانه بر اساس ویژگی![]() دارد.
دارد.
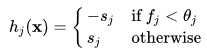
مقدار آستانه ![]() و قطبیت
و قطبیت![]() در آموزش و ضرایب
در آموزش و ضرایب ![]() تعیین شده است.
تعیین شده است.
در زیر نسخه ساده شده الگوریتم یادگیری آورده شده است.
ورودی: مجموعه ای از N تصویر آموزشی مثبت و منفی با برچسبهای ![]() . اگر تصویر یک چهره باشد
. اگر تصویر یک چهره باشد ![]() برقرار است.
برقرار است.
- مقدار دهی اولیه: انتساب وزن
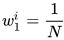 به هر تصویر i
به هر تصویر i - برای هر ویژگی
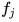 ، با
، با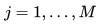
- نرمال سازی وزنها با جمع بستن با یک
- استفاده از ویژگی برای هر تصویر در مجموعه آموزشی، یافتن آستانه بهینه و قطبیت
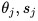 که خطای دسته بندی وزن شده را به حداقل میرسند، به طوری که رابطه زیر برقرار باشد:
که خطای دسته بندی وزن شده را به حداقل میرسند، به طوری که رابطه زیر برقرار باشد:
![]()
- انتساب یک وزن
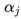 به
به 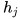 به طوری که نسبت عکسی با نرخ خطا داشته باشد. در این روش بهترین دسته بندی کننده بیشتر در نظر گرفته میشود.
به طوری که نسبت عکسی با نرخ خطا داشته باشد. در این روش بهترین دسته بندی کننده بیشتر در نظر گرفته میشود. - وزن هایی برای تکرار بعدی، مثلا
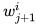 برای تصاویر i که به درستی دسته بندی شده است کاهش مییابد.
برای تصاویر i که به درستی دسته بندی شده است کاهش مییابد. - تنظیم دسته بندی کننده نهایی به
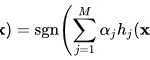 .
.
معماری آبشاری
دسته بندی کنندههای قوی در یک آبشار به منظور کمتر کردن پیچیدگی مرتب شده اند، که در آن هر دسته بندی کننده متوالی تنها توسط نمونه منتخبی که از دسته بندی کنندههای قبلی انتخاب شده است آموزش میبیند.
اگر در هر مرحله ای در آبشار دسته بندی کننده، زیر پنجره تحت بازرسی، را رد کند، پردازش بیشتری اجرا نمیشود و جستجو به سراغ زیر پنجره بعدی میرود. آبشار بنابراین فرم درختی میگیرد.
در مورد صورت ها، اولین دسته بندی کننده در آبشار، یعنی عملگرattentional ، تنها از دو ویژگی برای کسب یک نرخ منفی کاذب تقریبا 0% و یک نرخ مثبت کاذب 40% استفاده میکند. تاثیر این دسته بندی کننده واحد کاهش تقریبا نیمی از دفعاتی است که کل آبشار ارزیابی میشوند.
در آبشار، هر مرحله شامل یک دسته بندی کننده قوی است. لذا همه ویژگیها در چند مرحله گروه بندی میشوند که در آن هر مرحله تعداد مشخصی ویژگی دارد.
کار هر مرحله تعیین این است که آیا یک زیر پنجره مشخص قطعا چهره نیست یا ممکن است چهره باشد. یک زیر پنجره مشخص اگر چهره نباشد بلافاصله دور انداخته میشود.
ویژگیهای معماری آبشاری
- به صورت میانگین تنها 0.01% زیر پنجرهها مثبت هستند یعنی چهره هستند.
- زمان محاسباتی معادلی برای همه زیر پنجرهها سپری میشود.
- بیشتر زمان باید بر زیر پنجرههای مثبت سپری شود.
- یک دسته بندی کنده دو ویزگی میتواند نرخ تشخیص 100% را با نرخ FP 50% بدست آورد.
- دسته بندی کننده میتواند به عنوان اولین لایه یک سری از فیلترکنندههای منفی ترین پنجرهها عمل کند.
- لایه دوم با 10 ویژگی میتواند با پنجرههای منفی تری که از لایه اول آمده اند مقابله کند.
- این طبقه بندی به شدت پیچیده تر میشود و نرخ تشخیص بهتری کسب میکند. ارزیابی طبقه بندی کنندههای قوی تولید شده توسط فرآیند یادگیری میتواند سریعا انجام شود، اما این به اندازه کافی برای اینکه به صورت بلادرنگ اجرا شود سریع نیست.
یک فریم ورک ساده برای آموزش آبشاری در زیر آورده شده است:
- F= حداکثر نرخ مثبت کاذب قابل قبول به ازای هر لایه
- D= حداقل نرخ تشخیص قابل قبول به ازای هر لایه
- Ftarget= هدف کلی بر روی نرخ مثبت کاذب
- P= مجموعه ای از مثالهای مثبت
- N= مجموعه ای از مثالهای منفی
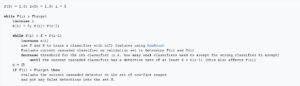
معماری آبشاری پیامدهای جالبی برای عملکرد دسته بندی کنندههای فردی دارد. فعال سازی هر دسته بندی کننده فقط به رفتار موارد قبلی بستگی دارد. لذا نرخ مثبت کاذب برای کل آبشار برابر است با:
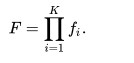
به طور مشابه، نرخ تشخیص برابر است با:
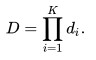
بنابراین، برای تطبیق نرخ مثبت کاذب که معمولا توسط تشخیص دهندههای دیگری کسب میشود. هر دسته بندی کننده میتواند با داشتن عملکرد به شدت ضعیف به کار آید. برای مثال، برای یک آبشار 32 مرحله ای برای کسب یک نرخ مثبت کاذب 10-6، هر دسته بندی کننده تنها نیازمند نرخ مثبت کاذب حدود 65% است. هم زمان، هر دسته بندی کننده نیاز است که نرخ تشخیص کافی را بدست آورد. برای مثال، برای کسب یک نرخ تشخیص حدود 90% هر دسته بندی کننده در آبشار فوق الذکر نیاز است که نرخ تشخیص تقریبا 99.7% را بدست آورد.
استفاده از Viola-Jones برای ردیابی شی
در ویدیوهای اشیای در حال حرکت، نیاز نیست که از تشخیص شی در هر فریم استفاده شود. در عوض، میتوان از الگوریتمهای ردیابی مانند الگوریتم KLT برای تشخیص ویژگیهایی در تشخیص کادرها و ردیابی حرکت بین فریمها استفاده کرد. نه تنها این سرعت ردیابی را با حذف نیاز به تشخیص مجدد شی در هر فریم بهبود میبخشد، بلکه مقاومت را بهبود میبخشد، چرا که ویژگیهای ساده تر نسبت به فریم ورک تشخیص Viola-Jones برای چرخش و تغییرات فتومتریک مقاوم تر است.



یک پاسخ
سلام. ممنون از مطالب خوبتون