


الگوریتم جنگل تصادفی (Random Forest) یک روش یادگیری ماشین است که از ترکیب چندین درخت تصمیم برای بهبود دقت و پایداری مدل استفاده میکند. هدف این مقاله بررسی مفهوم، عملکرد و کاربردهای الگوریتم جنگل تصادفی در مسائل طبقهبندی و رگرسیون است. جنگل تصادفی به دلیل مقاومت در برابر بیشبرازش (Overfitting) و توانایی کار با دادههای پیچیده، در مقایسه با روشهای سنتی مانند درخت تصمیم، مزایای قابل توجهی دارد. این مقاله برای افرادی که به دنبال درک عمیقتر از الگوریتمهای یادگیری ماشین هستند، نوشته شده است تا درک بهتری از الگوریتم جنگل تصادفی داشته باشند.

الگوریتم جنگل تصادفی یا Random Forest چیست؟
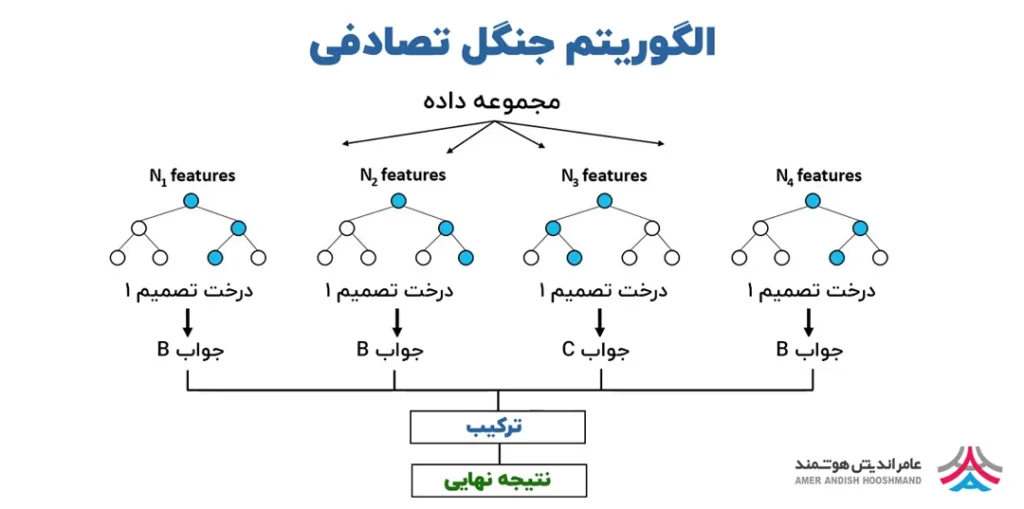
الگوریتم جنگل تصادفی یا رندوم فارست یک الگوریتم یادگیری ماشین است که برای طبقهبندی و رگرسیون استفاده میشود. این الگوریتم ترکیبی از چندین درخت تصمیمگیری (Decision Tree) است که بهصورت تصادفی انتخاب و ساخته میشوند. ایده اصلی پشت Random Forest این است که با ترکیب نتایج چندین درخت تصمیمگیری، دقت و قابلیت تعمیم مدل را افزایش داد و همچنین از مشکلاتی مانند: بیشبرازش (Overfitting) جلوگیری نمود.
الگوریتم جنگل تصادفی چگونه کار میکند؟
1. نمونهگیری تصادفی (Bootstrap Sampling)
در این مرحله، الگوریتم بهطور تصادفی زیرمجموعههایی از دادههای آموزشی اصلی را انتخاب میکند. این نمونهها ممکن است دارای دادههای تکراری باشند.
2. ساخت درخت تصمیمگیری (Decision Tree Construction)
برای هر یک از نمونههای تصادفی، یک درخت تصمیمگیری ساخته میشود. در هر گره از این درخت، الگوریتم بهطور تصادفی زیرمجموعهای از ویژگیها را انتخاب کرده و بهترین ویژگی برای تقسیم دادهها را انتخاب میکند.
3. رایگیری یا میانگینگیری (Voting or Averaging)
برای مسائل طبقهبندی، هر درخت تصمیمگیری یک رای برای کلاس نهایی میدهد و کلاس با بیشترین رای بهعنوان خروجی نهایی انتخاب میشود. برای مسائل رگرسیون، خروجی نهایی میانگین مقادیر پیشبینیشده توسط درختها خواهد بود.
مزایا و معایب الگوریتم جنگل تصادفی
مهمترین مزایای Random Forest شامل موارد زیر است:
- کاهش خطر بیشبرازش: با ترکیب نتایج چندین درخت، Random Forest معمولاً نسبت به الگوریتمهای تکدرختی، مانند درخت تصمیمگیری، کمتر دچار بیشبرازش میشود.
- دقت بالا: این الگوریتم معمولاً دقت بالاتری دارد، بهخصوص در دادههایی که پر از نویز هستند.
- پایداری: Random Forest در برابر دادههای متغیر و دادههای پرت پایداری بالاتری دارد.
- اهمیت ویژگیها (Feature Importance): این الگوریتم میتواند اهمیت ویژگیهای مختلف را در پیشبینی نهایی مشخص کند، که به تحلیل داده و بهبود مدل کمک میکند.
از جمله معایب رندوم فارست میتوان به موارد زیر اشاره کرد:
- زمان پردازش بالا: به دلیل ساخت تعداد زیادی درخت، زمان آموزش مدل میتواند طولانیتر باشد.
- پیچیدگی بیشتر: مدلهای Random Forest در مقایسه با مدلهای سادهتر مانند درخت تصمیمگیری، پیچیدهتر هستند و تفسیر آنها نیز دشوار است.
نمونه کاربردهای الگوریتم جنگل تصادفی در کسب و کارها
الگوریتم جنگل تصادفی (Random Forest) یکی از الگوریتمهای قدرتمند در یادگیری ماشین است که بهطور گسترده در صنایع مختلف برای حل مسائل پیچیده استفاده میشود. در ادامه به برخی از کاربردهای کلیدی این الگوریتم در کسب و کارها اشاره میشود:
1. تشخیص و پیشگیری از تقلب به کمک جنگل تصادفی (Fraud Detection)
در صنایع مالی، بانکها و شرکتهای کارت اعتباری از الگوریتم جنگل تصادفی برای شناسایی تراکنشهای مشکوک و جلوگیری از تقلب استفاده میکنند. این الگوریتم با تحلیل الگوهای تراکنشهای قبلی میتواند موارد غیرمعمول را شناسایی کرده و هشدارهای لازم را صادر کند.
2. پیشبینی و تحلیل مشتریان (Customer Segmentation and Churn Prediction)
در بازاریابی و مدیریت ارتباط با مشتری (CRM)، Random Forest برای تقسیمبندی مشتریان به گروههای مختلف براساس ویژگیهای مشترک استفاده میشود. همچنین این الگوریتم میتواند احتمال ترک (Churn) مشتریان را پیشبینی کرده و به کسب و کارها کمک کند تا استراتژیهای مناسبی برای نگهداشت مشتریان اتخاذ نمایند. با ترکیب این الگوریتم و سایر سیستمهای هوش مصنوعی میتوان مرکز تماس هوشمند را طراحی کرد و بدون هیچگونه دخالت انسانی به صورت شبانه روزی پاسخگوی نیازهای مشتریان بود.
3. توصیهگرها (Recommendation Systems)
در فروشگاههای آنلاین و پلتفرمهای محتوایی، الگوریتم جنگل تصادفی بهعنوان بخشی از سیستمهای توصیهگر استفاده میشود. این سیستمها بر اساس تحلیل رفتار کاربران و تاریخچه خرید یا بازدیدهای قبلی، محصولات یا محتوای مرتبط را به کاربران پیشنهاد میدهند.
4. پیشبینی فروش (Sales Forecasting)
در حوزه خردهفروشی و تولید، Random Forest میتواند برای پیشبینی تقاضا و فروش محصولات در آینده استفاده شود. این الگوریتم با تحلیل دادههای تاریخی، عوامل مختلفی مانند فصل، تبلیغات و تغییرات اقتصادی را در نظر میگیرد تا پیشبینیهای دقیقی ارائه دهد.
5. مدیریت زنجیره تأمین (Supply Chain Management)
در مدیریت زنجیره تأمین، الگوریتم جنگل تصادفی برای بهینهسازی موجودی کالاها، پیشبینی نیازها و مدیریت بهتر زنجیره تأمین استفاده میشود. این الگوریتم میتواند به کاهش هزینهها و افزایش بهرهوری کمک کند.
6. تحلیل احساسات و نظرات (Sentiment Analysis and Opinion Mining)
در تحلیل دادههای متنی مانند نظرات مشتریان در شبکههای اجتماعی، الگوریتم جنگل تصادفی میتواند برای تحلیل احساسات و طبقهبندی نظرات به مثبت، منفی یا خنثی استفاده شود. این اطلاعات به کسب و کارها کمک میکند تا بازخورد مشتریان را بهتر درک کنند و استراتژیهای خود را بهبود بخشند. به عنوان مثال، در چت بات باتاوا از این الگوریتم برای پاسخگویی 24 ساعته به مشتریان استفاده میشود.
مقایسه الگوریتم جنگل تصادفی با الگوریتم درخت تصمیم
الگوریتمهای درخت تصمیم (Decision Tree) و جنگل تصادفی (Random Forest) هر دو برای مسائل طبقهبندی و رگرسیون در یادگیری ماشین به کار میروند، اما تفاوتهای کلیدی در نحوه کارکرد و کاربردهای آنها وجود دارد.
درخت تصمیم یک مدل ساده و قابل تفسیر است که دادهها را به صورت سلسله مراتبی بر اساس ویژگیها تقسیم میکند. این الگوریتم سریع و شفاف است، اما ممکن است به شدت دچار بیشبرازش (Overfitting) شود، بهویژه اگر درخت بسیار عمیق باشد. در مقابل، در الگوریتم جنگل تصادفی از ترکیب چندین درخت تصمیم استفاده میشود که بهطور تصادفی و مستقل از هم ساخته شدهاند. این روش دقت بالاتری دارد و خطر بیشبرازش را کاهش میدهد، اما پیچیدهتر است و به زمان پردازش بیشتری نیاز دارد. الگوریتم جنگل تصادفی در برابر نویز و دادههای پرت مقاومتر است و مدل پایدارتری ارائه میدهد.
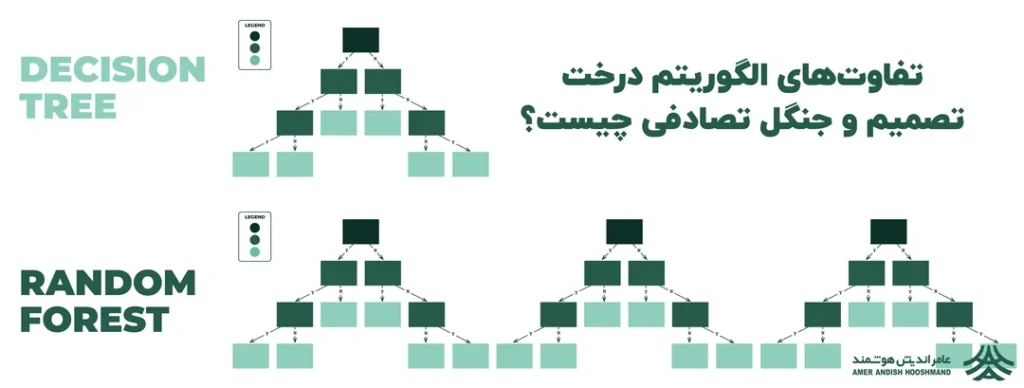
درخت تصمیم به دلیل ساختار ساده و قابل تفسیر بودن برای مسائلی که نیاز به تفسیر واضح دارند، مناسب است. در حالی که جنگل تصادفی به دلیل دقت بالاتر و توانایی مدیریت دادههای پیچیده، برای مسائلی که دقت و پایداری بیشتری نیاز دارند، انتخاب بهتری است، به عنوان مثال میتوان با ترکیب این الگوریتم با سایر ابزارها فرایند تبدیل صوت به متن را انجام داد، در حالی که انجام اینکار به کمک الگوریتم درخت تصمیم، ممکن نیست. در نهایت، انتخاب بین این دو الگوریتم به ماهیت مسئله، پیچیدگی دادهها، و نیاز به تفسیر مدل بستگی دارد.
جمعبندی
الگوریتم جنگل تصادفی (Random Forest) به عنوان یکی از قدرتمندترین ابزارهای یادگیری ماشین، توانایی فوقالعادهای در مدیریت دادههای پیچیده و جلوگیری از بیشبرازش دارد. با ترکیب چندین درخت تصمیم و استفاده از نمونهگیری تصادفی، این الگوریتم دقت بالایی را در پیشبینیها ارائه میدهد و به تحلیلگران امکان میدهد تا از دادههای خود بهرهوری بیشتری داشته باشند. در حالی که جنگل تصادفی به زمان و منابع بیشتری نسبت به درخت تصمیم نیاز دارد، اما نتایج پایدارتر و قابل اعتمادتری تولید میکند. در نهایت، انتخاب بین جنگل تصادفی و سایر الگوریتمها بستگی به نیازهای خاص پروژه و ویژگیهای دادههای مورد بررسی دارد.


