


افزودن ماژولی که بتواند فعالیت بخشی از مغز را تقلید کند میتواند از خطاهای رایج ایجادشده توسط مدلهای بینایی کامپیوتری جلوگیری کند.

عصب شناسان دانشگاه MIT با افزودن لایه جدیدی به مدلهای بینایی کامپیوتری که برای شبیه سازی V1 یعنی اولین مرحله از سیستم پردازش بینایی مغز طراحی شدهاست، توانستهاند راهی برای غلبه بر آسیبپذیری مدلهای بینایی کامپیوتری در برابر “حملات خصمانه” ایجاد کنند.
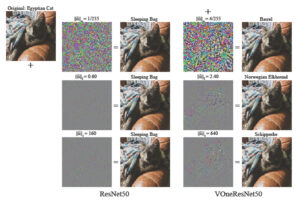
مقایسه تصاویر متخاصم با قدرت آشفتگی متفاوت.

شکل بالا تجسم بسیاری از انواع مختلف تخریب تصویر رایج را نشان میدهد. ردیف اول، تصویر اصلی و به دنبال آن خرابی ناشی از نویز است. ردیف دوم، خرابی ناشی از تارشدن و ردیف سوم، خرابی آب و هوا ردیف چهارم، خرابی دیجیتال را نشان میدهد.
مدلهای بینایی کامپیوتری معروف به شبکههای عصبی پیچشی را میتوان برای شناخت اشیاء، با همان دقتی که انسان اشیاء را تشخیص میدهد، آموزش داد. با این حال این مدلها یک نقص مهم دارند: تغییرات بسیار کوچک در یک تصویر که برای یک بیننده انسانی قابل مشاهده نیستند، میتواند باعث اشتباهات فاحشی مانند طبقهبندی یک گربه به عنوان یک درخت در ماشینها شود.
تیمی از عصبشناسهای دانشگاه MIT، دانشگاه هاروارد و IBM با افزودن لایه جدیدی به مدلهای بینایی ماشین به منظور تقلید از اولین مرحله سیستم پردازش بینایی مغز انسان، راهی برای کاهش این آسیبپذیری ایجاد کردهاند. در یک مطالعه جدید، آنها نشان دادند که این لایه به شدت قدرت مدلهای بینایی ماشین را در برابر این نوع اشتباهات بهبود دادهاست.
Tiago Marques فوقدکترای دانشگاه MIT و یکی از نویسندگان این مقاله پژوهشی میگوید: “در این مرحله از پردازش، تنها با ساخت مدلهای شبیه به قشر بصری اولیه مغز، ما پیشرفتهای قابلتوجهی در تشخیص انواع مختلف اختلالات و خرابیها میبینیم.”
شبکههای عصبی پیچشی اغلب در کاربردهای هوش مصنوعی مانند اتومبیلهای خودران، خطوط مونتاژ خودکار و تشخیص پزشکی استفاده میشوند. Joel Dapello دانشجوی تحصیلات تکمیلی دانشگاه هاروارد و نویسنده اصلی این تحقیق میگوید: “اجرای رویکرد جدید ما میتواند این سیستمها را مستعد خطای کمتر کند و بینایی این سیستمها را بیشتر شبیه انسان کند.”
James DiCarlo رئیس دپارتمان مغز و علوم شناختی دانشگاه MIT، محقق در مرکز مغز، ذهنها، ماشینها و نویسنده ارشد این مقاله میگوید: “فرضیههای علمی درباره چگونگی کارکرد سیستم بصری مغز، باید از نظر الگوهای عصبی داخلی و استحکام قابل توجه مغز، با آن مطابقت داشته باشد. این مطالعه نشان میدهد که دستیابی به این دستاوردهای علمی مستقیماً منجر به دستاوردهای مهندسی و کاربردی میشود.”
Martin Schrimpf دانشجوی کارشناسی ارشدMIT، Franziska Geigerدانشجوی بازدید کننده MIT و دیوید کاکس مدیر آزمایشگاه هوش مصنوعی AI Mats-IBM Watson نویسندگان دیگر این مطالعه هستند که در کنفرانس NeurIPS ارائه شده است.
تقلید از مغز انسان
تشخیص اشیاء یکی از عملکردهای اصلی سیستم بینایی است. تنها در کسری از ثانیه، اطلاعات بصری از طریق جریان بینایی قدامی به قشر گیجگاهی تحتانی مغز، جایی که در آن نورونها حاوی اطلاعات مورد نیاز برای طبقهبندی اشیا هستند، جریان مییابند. در هر مرحله از جریان قدامی، مغز انواع مختلف پردازش را انجام میدهد. اولین مرحله در جریان قدامی یعنی V1، یکی از شناختهشدهترین بخشهای مغز و شامل نورونهایی است که به ویژگیهای بصری ساده مثل لبهها پاسخ میدهند.
Marques میگوید: “تصور میشود که V1 لبههای موضعی و قسمتهای کوچکی از اشیاء و بافتها را شناسایی میکند و نوعی تقسیمبندی تصاویر را در مقیاس بسیار کوچک انجام میدهد. از این اطلاعات بعدا برای شناسایی شکل و بافت اشیاء در جهت پاییندست استفاده میکند. سیستم بینایی به این روش سلسله مراتبی جایی که در آن نورونها در مراحل اولیه به ویژگیهای محلی مانند لبههای باریک و کشیده واکنش نشان میدهند، ساخته شدهاست.”
سالهاست که محققان در تلاشند تا مدلهایی بسازند که بتوانند اشیاء و همچنین سیستم بینایی انسان را شناسایی کنند. امروزه سیستمهای بینایی کامپیوتری پیشرفته به راحتی توسط دانش فعلی ما در مورد پردازش بینایی مغز هدایت میشوند. با این حال عصبشناسان هنوز در مورد چگونگی اتصال کل جریان بینایی قدامی برای ساخت مدلی که دقیقاً آن را تقلید میکند، اطلاعات کافی ندارند. بنابراین آنها روشهایی را از شاخه یادگیری ماشین با هدف آموزش شبکههای عصبی پیچشی بر روی مجموعه خاصی از کارها استفاده کردهاند. با استفاده از این فرآیند، یک مدل میتواند پس از آموزش توسط میلیونها تصویر، اشیاء را شناسایی کند.
بیشتر این شبکههای پیچشی عملکرد بسیار خوبی دارند، اما در بیشتر موارد محققان دقیقاً نمیدانند که شبکه چگونه یک شیء را شناسایی میکند. در سال 2013، محققان آزمایشگاه DiCarlo نشان دادند که برخی از این شبکههای عصبی نه تنها میتوانند اشیاء را به طور دقیق شناسایی کنند، بلکه همچنین میتوانند پیشبینی کنند که چگونه نورونها در مغز نخستیها به این اشیاء بسیار بهتر از مدلهای جایگزین موجود پاسخ میدهند. با این حال، این شبکههای عصبی هنوز قادر به پیشبینی کامل پاسخها در طول جریان بینایی قدامی به ویژه در اولین مراحل تشخیص جسم یعنی مرحله V1 نیستند.
این مدلها همچنین در برابر حملات به اصطلاح خصمانه بسیار آسیبپذیر هستند. این به این معنی است که تغییرات کوچک در یک تصویر، مانند تغییر رنگ چند نقطه میتواند باعث شود که مدل به طور کامل یک شی را با شی متفاوت دیگر اشتباه بگیرد. در حالی که یک بیننده انسانی این نوع اشتباه را مرتکب نمیشود.
محققان به عنوان اولین گام در مطالعه خود، عملکرد 30 مدل را تحلیل کردند و دریافتند که مدلهایی که پاسخهای داخلی آنها بهتر با پاسخهای V1 مغز همخوانی دارند، نسبت به حملات خصمانه کمتر آسیبپذیر هستند. یعنی به نظر میرسد داشتن V1 که بیشتر شبیه مغز انسان است، مدل را قویتر کردهاست. برای آزمایش بیشتر و بهرهگیری از این ایده، محققان تصمیم گرفتند مدل V1 خود را بر اساس مدلهای عصبی علمی موجود ایجاد کنند و آن را در جلوی شبکههای عصبی پیچشی که قبلا برای تشخیص شیء توسعه داده شدهبود، قرار دهند.
هنگامی که محققان لایه V1 خود را که به عنوان یک شبکه عصبی پیچشی پیادهسازی شدهاست به سه تا از مدلها اضافه کردند، دریافتند که این مدلها در برابر تشخیص اشتباه در تصاویر خراب شده ناشی از حملات خصمانه، حدود چهار برابر مقاومت بیشتری نشان دادند. همچنین این مدلها نسبت به عدم تشخیص ناشی از خرابیهای دیگر که باعث مبهم یا تحریفشدن عکس شده بودند، کمتر آسیبپذیر بودند.
Cox میگوید: “حملات خصمانه یک مشکل بزرگ برای کاربرد عملی شبکههای عصبی عمیق است. این واقعیت که افزودن عناصر الهام گرفته از علوم اعصاب میتواند قدرت مدل را بهبود ببخشد، نشان میدهد که هنوز چیزهای زیادی وجود دارد که هوش مصنوعی میتواند از علوم اعصاب یاد بگیرد و بالعکس.”
دفاع بهتر
در حال حاضر، بهترین دفاع در برابر حملات خصمانه، یک فرآیند بسیار پرهزینه از مدلهای آموزشی برای تشخیص تصاویر تغییر یافته میباشد. یکی از مزایای مدلهای مبتنی بر V1 این است که به هیچ آموزش اضافی نیاز ندارد و علاوه بر حملات خصمانه، میتواند طیف گستردهای از اعوجاجها را نیز کنترل کند.
در حال حاضر محققان در تلاشند تا ویژگیهای کلیدی مدل V1 را که به آن اجازه میدهد در برابر حملات خصمانه، بهتر عمل کند را شناسایی کنند. این ویژگیها میتواند به آنها کمک کند تا مدلهای آینده را قویتر کنند. شناسایی این ویژگیها همچنین اطلاعات محققان در مورد چگونگی تشخیص اشیاء توسط مغز انسان را نیز بیشتر میکند.
Dapello میگوید: “یک مزیت بزرگ این مدل این است که ما میتوانیم مولفههای مدل را به جمعیتهای نورونی خاص در مغز نگاشت کنیم. ما میتوانیم از این روش به عنوان ابزاری برای یافتههای عصبشناسی استفاده کنیم و همچنین توسعه این مدل را برای بهبود عملکردش ادامه دهیم.”
بودجه این تحقیق توسط بنیاد PhRMA بنیاد PhDMA در رشته انفورماتیک، شرکت تحقیقات نیمه هادی، دارپا، انجمن تحقیقات نیروی دریایی ایالاتمتحده و آزمایشگاه هوش مصنوعی MIT-IBM Watson تامین شدهاست.


